Scalable job processing with KEDA in Kubernetes
KEDA is a Kubernetes-based Event Driven Autoscaler. In this blog, you will see how we migrated a legacy integration service into Kubernetes and use KEDA for scaling. It explains a solution for short and long-running jobs that responds fast, is running resilient against deployments, and will be controlled based on load.
As in all areas of life, the same applies to software development: Everything is always changing.
Our LeanIX platform supports integrations with third-party systems, some of them have been in use for years. In the course of the transition to Kubernetes and for better scaling, we decided to migrate an existing integration microservice to Kubernetes without rewriting the code completely.
Integrations - and also our LeanIX integration - commonly works based on jobs. This means the integration reads data from two systems (LeanIX and a Foreign System) either completely or only partially, compares it and synchronizes differences to the other system. We call this a "synchronization" and it is an asynchronous task. The integration is executed as a job that can take a short or a very long time for processing depending on parameters like:
- the amount of data in the LeanIX workspace
- the amount of data in the foreign system workspace
- the type of the synchronization (full workspace synchronization or partial synchronization of known objects)
In our old integration, we noticed two symptoms in particular that were unpleasant and that we wanted to improve. On the one hand, the job execution times vary extremely, ranging from 5 seconds to 6 hours, and on the other hand, it sometimes happened that jobs set at peak times, piled up and had to wait a long time before they could be processed. This leads to the next questions:
- How can we achieve to start the execution of a job very fast and avoid waiting until a Kubernetes worker Pod is up?
- How can we ensure Kubernetes will not abort a running Pod that is currently doing a synchronization job run?
- How can we dynamically scale to be prepared for upcoming job peaks but avoid wasting resources on Kubernetes?
The legacy Integration system
Let's start with a view of the legacy integration system that runs on a dedicated server.
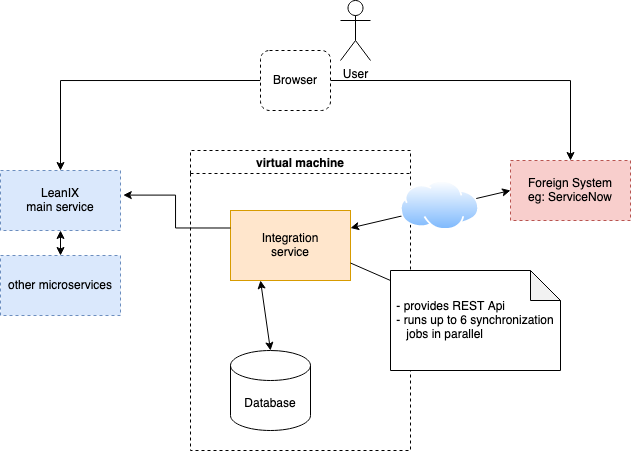
The legacy integration was one microservice that run up to 6 synchronization jobs in parallel. Per region, only one microservice was deployed. We limited the job processing to 6 to limit the resource consumption on the single server. However, the configuration of the memory was the deciding factor for the limitation to 6, since this setting is strongly dependent on the data. The microservice already provided the logic to create jobs for a synchronization, persist them into the database and execute them asynchronously.
The Migration to Kubernetes
How we did the migration
One major goal for the engineering team was to keep as much of the existing code and project structure untouched as possible because the integration is complex and matured over multiple months and years. We identified in an early stage just running the "old" docker container inside a Kubernetes pod will not be enough and make no sense for a company that is growing and needs scaling options.
To meet the requirements above, we decided to introduce KEDA as an autoscaler. As our service was not ready for KEDA we decided to extend our legacy code and to introduce 3 different Roles in which the service could be deployed and run.
In summary, the complete migration can be described in these steps:
- forking the existing integration microservice (The legacy microservice is still running and therefore we avoid touching this code.)
- implement the 3 different roles, adapt start scripts and pass them while starting the application
- create a local docker compose setup for testing purposes
- add configurations for the Kubernetes deployment for each defined role
- deploy all services into Kubernetes (the legacy integration continues to run in parallel)
- do a migration for each customer integration that moves the "customer" from the legacy to the Kubernetes system
New Kubernetes integration overview
The new target system consists of three different services and KEDA running in Kubernetes. The three services are built from one code base and merely started in different roles.
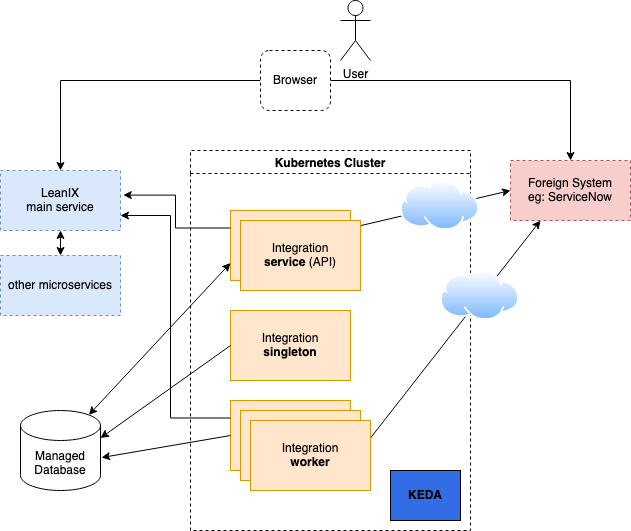
Here is a gist of the three roles:
service- Responsibility:
- provides the microservice REST API for the frontend and webhooks callbacks
- creates new jobs based on user interaction
- Number of instances: 2 (for availability reasons)
- lifecycle:
- started as a dropwizard service
- controlled by Kubernetes
- Responsibility:
singleton- Responsibility:
- computes number or required workers based of queued jobs
- creates new jobs based on fixed cron pattern (used for synchronizations that should run periodically)
- creates new "partial" jobs based on detected changes
- do some cleanup tasks
- Number of instances: 1
- lifecycle:
- started as a dropwizard task
- controlled by Kubernetes
- Responsibility:
worker- Responsibility:
- polls the database for queued jobs
- picks up queued jobs and do the integration run
- Number of instances: 1-n (scale by KEDA)
- lifecycle:
- started as a dropwizard task that will terminate itself at the end of its lifecycle
- NOT terminated by Kubernetes
- Responsibility:
The concept of workers and their lifecycle
As you can see above, the worker instances are responsible to process a synchronization run and as more workers are running as more jobs can be processed at the same time.
But there are still some questions we need to find a solution for:
a) How can we start and stop worker pods in relation to the number of queued jobs?
b) The procession time of a job is quite different and depends on the synchronization configuration and customer data. If a worker pod is stopped by Kubernetes during a job run, the whole job is failing. So, how can we prevent Kubernetes will not stop a worker? And how can we achieve that worker instances will not be running for too long and be updated when a new version is deployed?
The solution to that questions can be broken down into three parts:
- The singleton service:
The singleton service "computes" the number of workers that are required to process all queued jobs. If no job is queued, at least one worker instance should be running to react as fast as possible on potentially added jobs. The number of computed worker instances is persisted into a database table calleddesired_pod_count. - KEDA:
KEDA is a Kubernetes-based Event Driven Autoscaler we installed in our environment. One additional part of the new integration deployment is a KEDA configuration that defines a PostgreSQL Trigger configuration which is connected to the database tabledesired_pod_count. This enables the KEDA operator to read the calculated worker count and to start new worker pods ifdesired_pod_countis larger than the running worker pods. - The worker service:
Each worker service can process one or more jobs in parallel and it claims queued jobs from the database by itself. The lifecycle of a worker is fully controlled by the service itself (see the 'Worker State Machine') and ends only if no job is currently in progress and the service was up at least for 30 minutes. The current status of a worker is written into the database tableworker_lifecycleand evaluated from thesingletonservice because this information is required to compute the worker count.
Mostly KEDA is used to start new resources based on events. If we would stick to this pattern, for each new queued job a new worker service has to be started only responsible for a single job. But we don't follow this pattern.
The approach we did works differently: KEDA polls the database tabledesired_pod_countand ensures the defined number of resources (worker) are running. This guarantees that always enough workers are up and running. The worker itself pulls queued jobs and processes them!
The Worker State Machine
One crucial aspect of our solution is the lifecycle of the worker pods, which is fully controlled by the worker itself. KEDA will only destroy worker pods if they are running for an unexpected long long time, which should normally never happen.
The end of a worker lifecycle depends on the uptime and the fact whether a job is currently being in process or not.
The following diagram shows the worker’s state transitions.
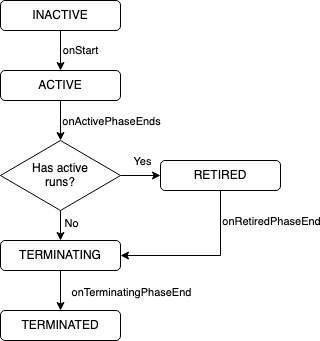
- INACTIVE: The initial status when the service is started
- ACTIVE: A phase that is active for 30 minutes. Only in this phase does the worker actively claim queued jobs
- RETIRED: During this phase, the worker no longer actively claims jobs. Jobs that are currently processed will be continued.
- TERMINATING: A grace period before shutting down. The main reason for this phase is to make the coordinator aware of the worker status change and adjust the desired job number before KEDA detects the pod shutdown.
- TERMINATED: The worker shuts itself down immediately when it reaches this phase
Computation of required workers
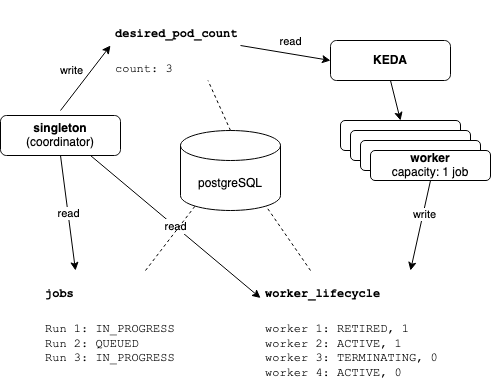
The worker count computation is realized inside the singleton service and done each 5 seconds. The calculation of the desired pod follows these rules:
desiredActiveWorkers = (ongoing_jobs - runs_in_retired_workers) / WORKER_CAPACITY + 1Desired Pods = Math.max(desiredActiveWorkers, MINIMUM_ACTIVE_WORKERS) + retired_workers_count
- ongoing_jobs: Number of jobs that are claimed and running at the time of calculation
- runs_in_retired_workers: The jobs that are being processed by retired workers
- retired_workers_count: Number of workers that are retired, but still not terminated
- WORKER_CAPACITY: Number of jobs a worker can process in parallel
- MINIMUM_ACTIVE_WORKERS: The number of additional workers on stand-by mode to handle a sudden increase of load (2 for our setup)
At first glance, the calculation of the workers seems to be incomplete, since the QUEUED jobs are not considered. But because the desiredActiveWorkers take care that always one more "idle" worker is available, a QUEUED job will find its worker.
The WORKER_CAPACITY is one more option you can use to fine-tune the system based on the concrete use case. When set to 1 only one job will be processed per worker which leverages the highest encapsulation of processing. If it is set to 2, two jobs are running per worker which will reduce the number of worker pods and therefore the resources. The downside of a 2 capacity setup could be that an unexpected crash of one job (maybe due to a programming error in combination with input data) causes a failure of all jobs of the worker.
A Keda configuration for workers
Here is an example of the KEDA configuration we use to control the worker scaling:
apiVersion: keda.sh/v1alpha1
kind: ScaledJob
metadata:
name: integration-servicenow-worker
spec:
jobTargetRef:
activeDeadlineSeconds: 32400 # Specifies the duration in seconds relative to the startTime that the job may be active before the system tries to terminate it
template:
<<: <%= partial 'worker-template' %>
pollingInterval: 15
envSourceContainerName: integration-servicenow-worker
successfulJobsHistoryLimit: 5
failedJobsHistoryLimit: 5
maxReplicaCount: 10
rolloutStrategy: gradual
scalingStrategy:
strategy: default
triggers:
- type: postgresql
metadata:
host: <%= databaseHost %>
port: "5432"
dbName: <%= databaseName %>
userName: <%= databaseUserName %>
sslmode: require
passwordFromEnv: POSTGRES_PASSWORD
# Attention: the result of the query will be divided by the number of current pods, and then compared to the value stored in desired_pod_count
query: "SELECT count FROM desired_pod_count"
targetQueryValue: '1'
activeDeadlineSeconds: 32400-> KEDA's operator will terminate the pod after 9 hoursmaxReplicaCount: 10-> scales the target resource up to 10 workersrolloutStrategy: gradual-> This setting controls KEDA to not stop a running worker pod after a new version of the worker service is deployed. This is important to avoid a crash of a running job.
Does KEDA work as expected?
After the system is deployed into the Kubernetes clusters, we want to verify that KEDA scales the worker pods as expected. The expectation for the current configuration is at least one worker on an idle job state and an upscaling up to 10 when jobs are piling up.
To verify that on Azure we use this Kusto query starting on KubePodInventory:
KubePodInventory
| where Namespace == "integration-signavio"
| where Name contains "integration-signavio-worker"
| where ContainerName !contains ("istio-")
| distinct PodUid, Name, ClusterName, TimeGenerated, ContainerStatus
| where ContainerStatus == "running"
| summarize count() by ClusterName, TimeGenerated
| render timechart 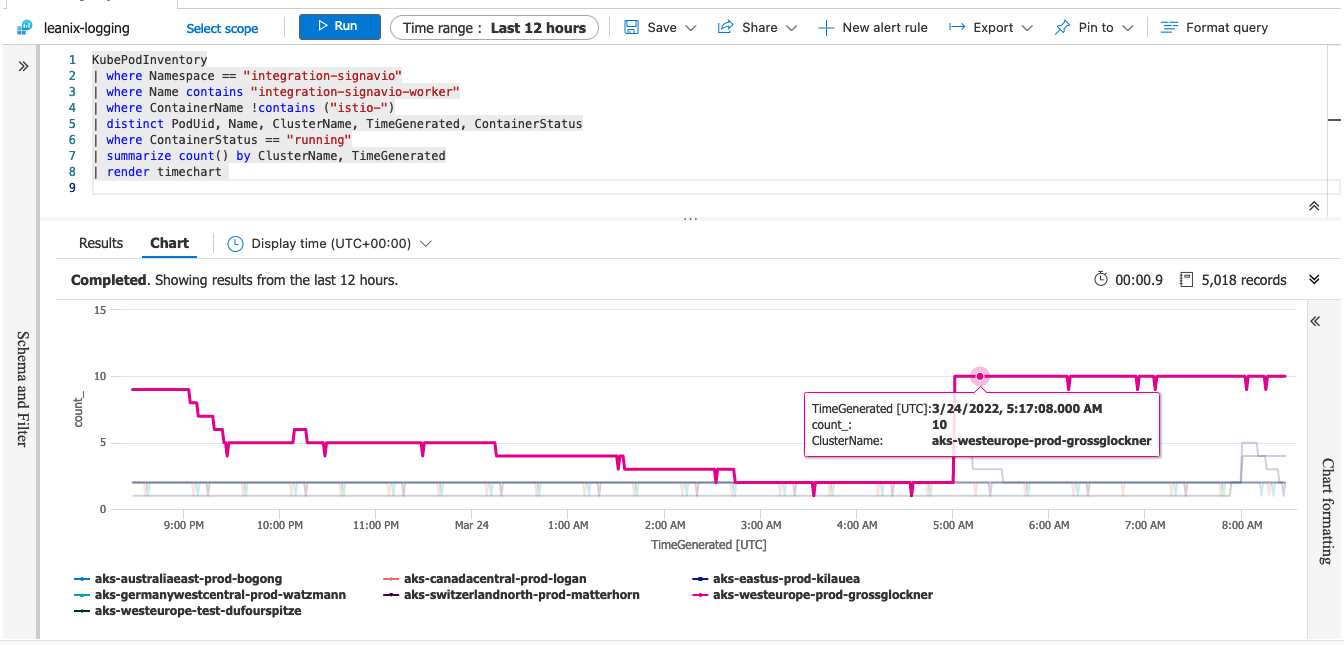
The time chart shows pretty clear that over the night only 1-2 worker pods are up and at 5am in the morning up to 10 workers are running. The reason for the 5am burst is because at this time a cron job creates for some customer integrations a synchronization job. Although the singleton instance "computes" at this time a higher worker request of 11 and writes that into desired_pod_count, KEDA limits the number of worker pods only up to 10 because of its configuration maxReplicaCount: 10. This configuration option makes it pretty easy to limit the resource usage on the cluster but also processes even a huge number of jobs over time.
Summary
I introduced how we moved from one single microservice that supports only a fixed number of parallel job processing to a dynamic solution running on Kubernetes. Although the new system is based on the legacy business code, we added just a new concept on top that realizes an asynchronous job processing controlled by KEDA.
The solution offers these advantages:
- fast processing of new enqueued jobs because one worker-pod is always up and able to claim and start a job immediately
- support of long-running jobs without interruption by Kubernetes
- high scalability to process jobs in parallel
- based on KEDA's configuration it is easy to limit the overall resource usage
- option to balance the encapsulation of job processing (It is either possible to execute only one job or multiple jobs per worker in parallel)
- deployments of new releases will never interrupt worker pods that are currently processing a job
Published by...

Ralf Wehner
Visit author page