Ship features faster by introducing an OpenAPI code generator
We want to focus on what we love doing - shipping great features to our customers. In this blog post, we explain how an OpenAPI client code generator supports us in achieving this goal. We also show how we've integrated it into our build pipeline.
When building a new application, you probably want to move fast. In the backend, this involves frequent changes and adjustments of APIs. Those can be, e.g., adding a new endpoint, changing its request parameters, or updating response models. In the frontend, the corresponding interfaces and HTTP services need to be updated as well. Doing this manually can be error-prone and might cost your team time and effort that it could better invest in creating real customer value.
However, this process can be automated. Leveraging the OpenAPI Specification allows us to ensure that frontend and backend stay in sync. If your backend provides an OpenAPI document, there are various tools that can generate client code from it.
The OpenAPI document
The OpenAPI document describes your API in a JSON or YAML format. It provides information about how to interact with the API endpoints. Here's an example taken from the Swagger Petstore document. You can also play with it in the Swagger Editor.
paths:
/pet:
post:
tags:
- pet
summary: Add a new pet to the store
description: Add a new pet to the store
operationId: addPet
responses:
"200":
description: Successful operation
content:
application/json:
schema:
$ref: "#/components/schemas/Pet"
"405":
description: Invalid input
requestBody:
description: Create a new pet in the store
required: true
content:
application/json:
schema:
$ref: "#/components/schemas/Pet"You can see that we're able to define what the request and response bodies should look like. In the above /pet POST operation, both request and response body refer to the Pet schema, which is defined in the components property of the OpenAPI document:
components:
schemas:
Pet:
type: object
required:
- name
- photoUrls
properties:
id:
type: integer
format: int64
example: 10
name:
type: string
example: doggie
category:
$ref: "#/components/schemas/Category"
photoUrls:
type: array
items:
type: stringOur hybrid way of API development
When it comes to developing an API, and by extent writing an OpenAPI document, two approaches exist:
- Design-first: A contract upon which all involved parties agree is written first. It is then used as the reference for the implementation.
- Code-First: The API is implemented first. An API specification file such as the OpenAPI document can then be generated from it.
Each way has its own set of advantages and disadvantages. Let's review them from our point of view, keeping in mind that we want to auto-generate a client from an OpenAPI document. For a more general analysis of these two approaches, one can refer to this blog post from Swagger.
Design-First
Using a design-first approach usually results in a more consistent API, as it enforces developers to put thoughts into the "look & feel" of the API without having to deal with implementation details. It also helps to iterate on its design quickly, while having continuous feedback from the targeted users of the API.
On the other hand, this approach has a serious drawback when it comes to auto-generating a client from the document: It is hard to ensure that the API implementation matches the OpenAPI document. Because we generate the client from the OpenAPI document, a minor difference in the implementation can result in a broken client.
Code-First
Using a code-first approach may result in a less consistent API, as many developers collaborate on the backend. A typical task used to develop APIs goes along the way of "Add POST endpoint Foo with response body Bar". Undeniably, this removes the global vision one has by working on a schema document, hence the possible creation of inconsistencies between different endpoints.
However, this approach allows our team to confidently generate an OpenAPI document as the document is directly generated from the code. This ensures no divergences between the document and the implementation.
Our approach: Design-First, Code-Second
We find that using a combination of the two approaches is what works best for our team. But what is this "hybrid way" about?
When bootstrapping a new API targeting one of our web applications, we usually start our first iteration in a design-first fashion. This allows both backend and frontend developers to collaborate, as there is no specific knowledge required. Not only does this ensure our team that the resulting API will match the frontend requirements, but it also brings a global overview of where we are heading to the entire team.
Once we have validated this first iteration we start our second iteration, but this time in what we call a code-second fashion. We implement the resulting design of the first iteration but also start auto-generating an OpenAPI document out of it. Any further iteration also makes use of the auto-generated document. As a result, the OpenAPI client can use the auto-generated document file with the confidence that it matches the backend exactly.
Generating our OpenAPI document
Because our backends are written in Kotlin and Spring, we can use Springdoc for generating an OpenAPI document file from our code. Nevertheless, if you are using a different backend stack, similar tools exist. Springdoc does most of the work for us, but some extra customization can be added with the help of annotations, e.g., to our Controllers and DTOs. Let's have a look at what the previously shown Petstore example would look like:
@Schema(description = "Schema used to create a new Pet in the store")
data class PetRequestDto(
val id: Int,
val name: String,
val category: Category,
val photoUrls: List<String>
)
@PostMapping("/pet")
@Operation(
summary = "Add a new pet to the store"
description = "Add a new pet to the store"
)
fun savePet(@RequestBody pet: Pet) = petService.save(pet)The generated document is then accessible as a static file that can be used to generate our client.
Generating our OpenAPI client files
We are using ng-openapi-gen for generating our client. It will generate TypeScript interfaces and Angular services. Let's try it out and feed it with the Swagger Petstore document:
npx ng-openapi-gen -i https://raw.githubusercontent.com/swagger-api/swagger-petstore/master/src/main/resources/openapi.yaml -o petstore-generated --indexFile true --skipJsonSuffix true --module false --modelIndex false --serviceIndex false --ignoreUnusedModels falseThe generated folder contains all the TypeScript interfaces and Angular services needed for interacting with the Petstore backend. You can take a look at the generated code on GitHub.
Now it would be nice to get the generated client into our existing code base in an automated way!
Automating the process with GitHub workflows
In the following, we show how we can leverage GitHub Actions to re-generate the client files when the OpenAPI document has changed on the backend side.
Backend workflow
In our backend repository, we've created a workflow that should notify the frontend when the OpenAPI document has changed. It uses a repository_dispatch event to trigger a workflow run in the frontend repository. You can read more about this event type in the GitHub documentation.
name: Notify frontend about API changes
on: workflow_dispatch
jobs:
publish-spec:
if: github.ref == 'refs/heads/main'
runs-on: ubuntu-latest
steps:
- name: Notify frontend
uses: peter-evans/repository-dispatch@v2
with:
token: ${{ env.GITHUB_TOKEN }}
repository: leanix/valuestreams-ui
event-type: openapi-document-updated
client-payload: '{ "name": "vsm-discovery", "sha": "${{ github.sha }}" }'With the workflow_dispatch trigger, we allow this action to be manually triggered by the backend developers of our team after their changes have been merged to the main branch. This on-push approach also helps us reduce our GitHub actions bill.
We need to pass some parameters to the repository-dispatch action:
repository: The name of the repository where the event should be dispatched toevent-type: A name to identify the eventclient-payload: Additional payload that should be sent with the event. Here we pass the name of the backend repository and the commit hash.token: We're using the token of ourleanix-ciGitHub user since we want it to be the author of the workflow run
Now we can listen to this event in our frontend repository.
Frontend workflow
Our workflow in the frontend repository will be triggered by any repository_dispatch event with the type openapi-document-updated. It will:
- fetch the updated OpenAPI document from a static endpoint of our backend
- based on the fetched document, generate the OpenAPI client in a temporary folder
- execute a Node script to move the generated files to the destination folder
- push the file changes to a new branch
- create a pull request
name: Update OpenAPI client files
on:
repository_dispatch:
types: [openapi-document-updated]
jobs:
generate-openapi-client:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
with:
token: ${{ env.GITHUB_TOKEN }}
- name: Install dependencies
run: npm ci
- name: Generate client in temporary folder
run: npx ng-openapi-gen -i https://eu.leanix.net/services/vsm-discovery/v1/openapi -o ${{ runner.temp }}/.openapi-generated/${{ github.event.client_payload.name }} --ignoreUnusedModels false --indexFile true --skipJsonSuffix true --module false --modelIndex false --serviceIndex false
- name: Copy generated client files to destination folder
run: npx ts-node ./scripts/copy-generated-openapi-files.ts -- ${{ github.event.client_payload.name }} ${{ runner.temp }}/.openapi-generated/${{ github.event.client_payload.name }}
- name: Push changes and create pull request
uses: peter-evans/create-pull-request@v4
with:
branch: openapi-generated/${{ github.event.client_payload.sha }}
base: ${{ github.event.repository.default_branch }}
title: Update OpenAPI client files for ${{ github.event.client_payload.name }}
author: leanix-ci <leanix-ci@users.noreply.github.com>
assignees: leanix-ci
committer: leanix-ci <leanix-ci@users.noreply.github.com>
commit-message: Update OpenAPI client files for ${{ github.event.client_payload.name }}
body: 'This PR has been generated to reflect the backend changes of ${{ github.event.client_payload.name }}. Link to related changes: ${{ github.server_url }}/${{ github.event.client_payload.name }}/commit/${{ github.event.client_payload.sha }}" }}'
token: ${{ env.GITHUB_TOKEN }}
labels: openapi-generated
delete-branch: trueAgain, we're using our leanix-ci user for authoring the pull request. The copy-generated-openapi-files.ts is a small Node script that copies the generated files from the temporary runner folder to the correct feature library folder. Using the commit hash from the event payload, the pull request body contains a link to this commit in the backend.
Let's try it out!
Suppose we've made a small change to our backend by adding an optional id property to the body of an upsert request. This property should be optional because we only know the id of our resource when updating it, not when creating it.
After merging our backend changes, we need to trigger the backend workflow, which itself triggers the above-shown frontend workflow. Already after a minute, we can see the generated pull request:
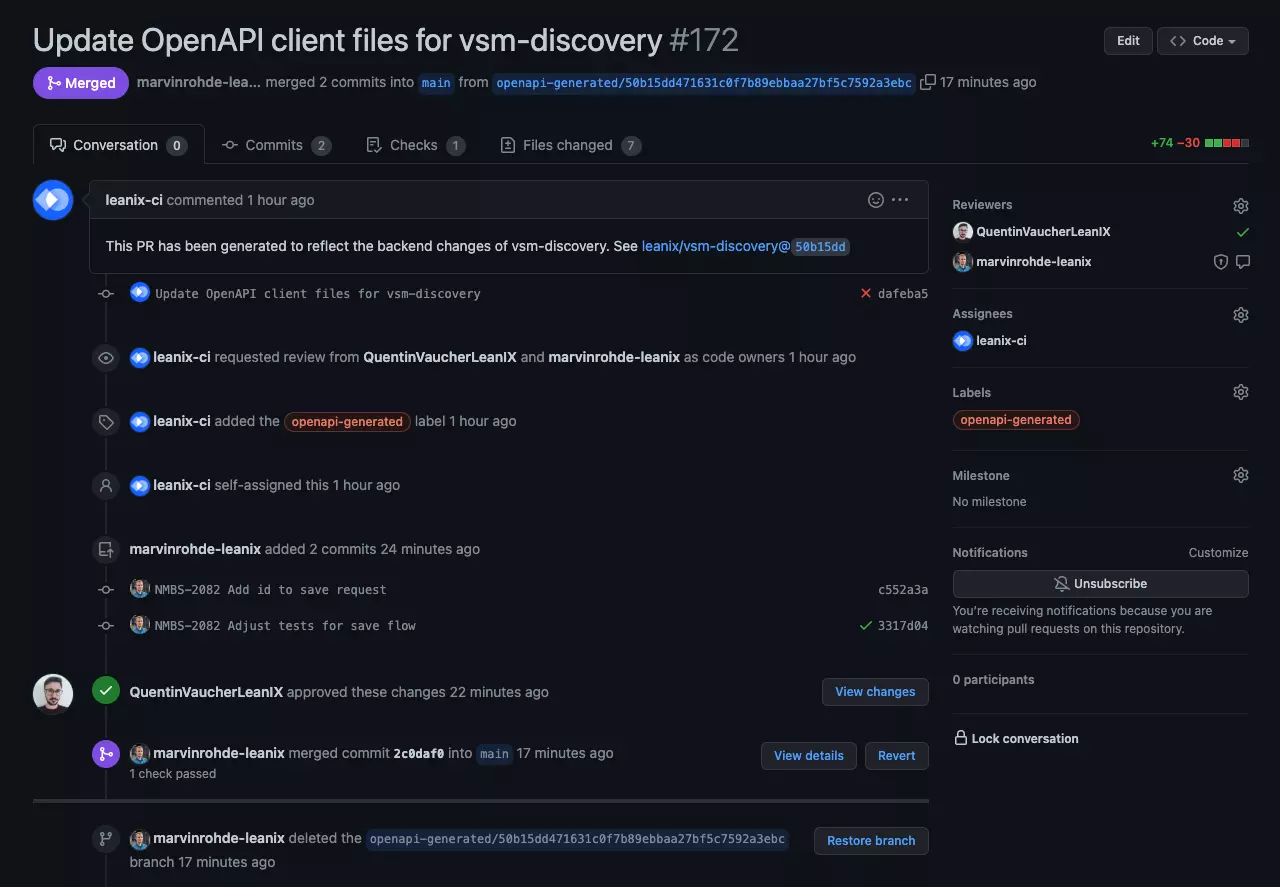
You can see that we've added some commits to this pull request. In the commit messages, you can read that we've added the id to our save request and also adjusted some related tests.
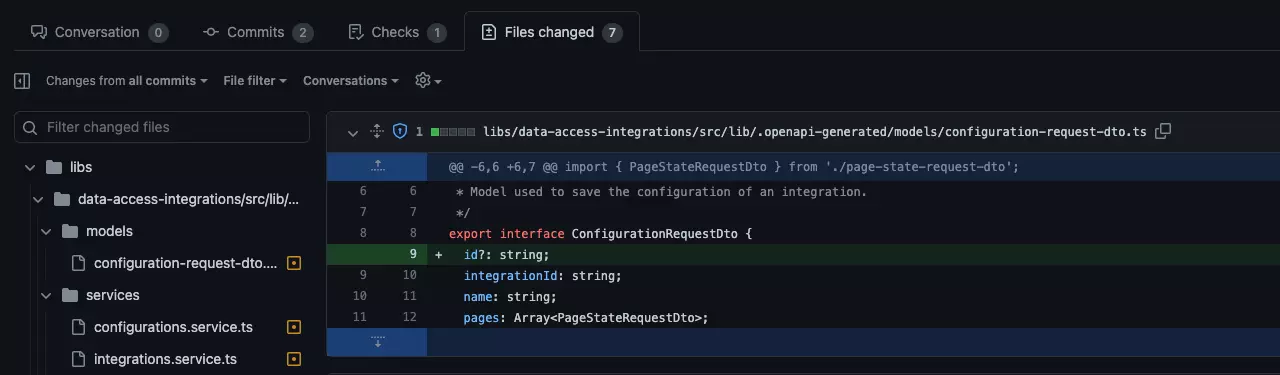
Here you can see that the generated request model contains the new id property that needs to be added.
Conclusion
By now, our team has had this workflow in place for over a month, and it has already saved us a lot of time. Here are some benefits that we can see:
- Frontend developers can easily understand what has changed in the backend by having a look at the file changes of the pull request.
- Symmetrically, backend developers get more awareness about how changes in the codebase impact the frontend.
- As code owners of the repository, we will be assigned as reviewers and receive notifications about new pull requests.
- By the pull request approach, we're able to react to breaking changes quickly before they lead to errors in production.
- Ideally, failing unit tests will also point us to breaking changes.
- All the copy & paste work for adding a new endpoint to a service, including its request and response models, is a thing of the past now.
Thank you for reading this blog post. Maybe you'll consider introducing an OpenAPI generator when developing your next application? We would appreciate your opinion on this topic.
Footnotes
1. The OpenAPI Specification is only applicable to RESTful APIs. ↑
2. Read more about how and why we invest effort in reducing our GitHub actions bill in this blog post. ↑
3. You can find out more about code owners in the GitHub documentation. ↑
Published by...

Marvin Rohde
Visit author page

Quentin Vaucher
Visit author page
💬 Discuss this article on Twitter