How to procrastinate jobs successfully
This post is about how we moved from a cronjob to a python based task queue and the learnings we had on the way.
I'm part of a data science team at LeanIX that builds python based micro services.
Most of my team's services need to crawl data or do computations regularly. Whenever that's the case, our go to solution is to create a kubernetes cronjob, that handles all tasks. Since this is essentially one job looping over every task, it's fast to implement and easy to monitor. We catch if a task fails and send a notification once all tasks are completed. In order to restart the whole job, you just need one kubernetes console command.
So why switch to a task queue?
Let's assume our new service is a restaurant. We start out with a cronjob waiter (worker). Every 15 minutes the waiter goes to every table and asks for an order. As long as the waiter needs less than 15 minutes you're fine. But if the number of tables (tasks) keeps increasing, the waiter will need more than 15 minutes to process all tasks at some point. In order to enable horizontal scaling we decide to switch to a task queue. The waiter picks a task from the queue, e.g. ask table 4 for orders, and processes it. After 15 minutes the task to ask table 4 for orders is written to the queue again. If the waiter needs more than 15 minutes to process all tasks and the number of tasks in the queue keeps increasing, we can just increase the number of waiters without assigning specific tables to waiters.
Another advantage is that tasks can be triggered independently from another. This is great if you need to manually or automatically execute a single task or a subset instead of all tasks. It also enables eventual consistency by listening to events or webhooks and triggering tasks accordingly. For our restaurant service this would mean that guests don't need to wait for the waiter to come to the table every 15 minutes anymore. Instead, they can call the waiter whenever they want to order something.
By now our customers can order food and drinks, but the waiter doesn't have a task to serve food yet. With the cronjob waiter we would need to integrate serving food into the existing task or create a new cronjob that runs every 10 minutes. For the task queue waiter we just add another task to serve food and add it to the queue as soon as it's ready.
Available options
Now that we decided to switch to a task queue, we need to choose one of the many available frameworks in python.

- celery popular package that supports different backends (e.g. Redis, SQLAlchemy) and brokers (e.g. Redis, RabbitMQ)
- dramatiq simpler alternative that supports Redis and RabbitMQ
- python-rq built on Redis
These are great packages, but we went with procrastinate. Besides the great naming this has two reasons:
- It supports PostgreSQL as a message queue, which is already in use in our service. So we don't add another dependency.
- Procrastinate is asynchronous at core, which is great as our service is also async and we don't have to mix synchronous and async code.
Core Principles
You can define a task by decorating a function:
@app.task
async def take_order(table_number):
orders = []
for guest in guests_at_table(table_number):
orders.append(await wait_for_order(guest))
return ordersBy deferring a task, a job is written to the queue and a worker will pick it up:
async def main():
await take_order.defer_async(table_number=42) Procrastinate jobs have one of four states:
- todo: The job is ready to be picked by a worker.
- doing: The job is currently being processed by a worker.
- failed: The job failed.
- succeeded: The job succeeded.
These are just the basics, but for a proper tutorial please check out the amazing Procrastinate documentation!
Our learnings
Monitoring
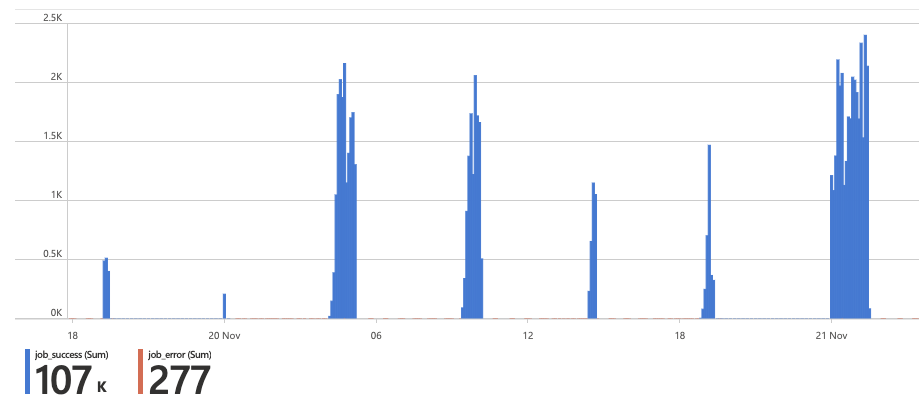
Procrastinate uses structured logging which is great for monitoring, e.g. we parsed the logs to build an azure workbook showing the number of succeeded and failed jobs. As PostgreSQL is used as a message queue it's also easy to take a look at the according tables if you have some experience in SQL.
Some experiences with locks
There are two kinds of locks in procrastinate: lock and queueing_lock.
- If two or more jobs have the same queueing_lock only one may be in the queue with state todo.
- If lock has the same value in multiple jobs, only one of them can be in doing at a time.
Both caused some problems for us. If a job with lock=locked is being processed and the worker dies, it's stuck in that state and no other job with that lock can be started. We added a periodic task that checks for these stalled jobs and resets them to todo.
If you also use queueing_locks this can still cause a dead lock.
- job1
lock=locked,queueing_lock=q_locked,status=doing
- job2
lock=locked,queueing_lock=q_locked,status=todo
In this state job2 can not be processed as job1 is stuck in doing and the recovery task can not set job1 to todo as job2 is already enqueued.
So what's our learning? Use locks only where necessary. You can avoid using locks and these problems if your jobs can run concurrently and are idempotent, which means that you can safely run one job multiple times.
Keep the job queue clean
At the start we kept every job in the queue in order to have the best possible monitoring. This caused degraded performance after some days, because the number of rows in the queue increased steadily and the SQL statements got slower.
By deleting finished jobs directly, you can keep your job queue small. Thanks to structured logging you also don't lose any information.
Wrap up
Our default solution for crawling data is still a cronjob as it's just so easy to setup. However, with the learnings above we know how to use a simple task queue that is scalable and more flexible than a cronjob. Since we use PostgreSQL most of the time anyway, it does not add additional dependencies and is easy to use in an asynchronous service.

Published by Philipp Glock
Visit author page