Building an AI Assistant for Onboarding
And why we’re not launching it
Recently, a customer approached us as they were about to onboard 100 new internal users to their LeanIX EAM. They proposed creating an AI assistant based on our documentation to help first-time users with their questions. The goal was to answer at least 80% of product-related questions without further interaction with an enablement team on customer side. Intrigued by this idea, we built a feasibility prototype together with the customer based on Azure OpenAI. In this blog post, we'll delve into the process and technologies we employed while building the AI assistant - “creatively” codenamed DocsGPT.
Prototype Implementation
Providing an overview of the entire architecture, let's take a bird's eye view of the system. While it may not be necessary to comprehend all the details at this moment, we will gain a clear understanding of how each component functions and its overall integration as we delve deeper into its specifics.
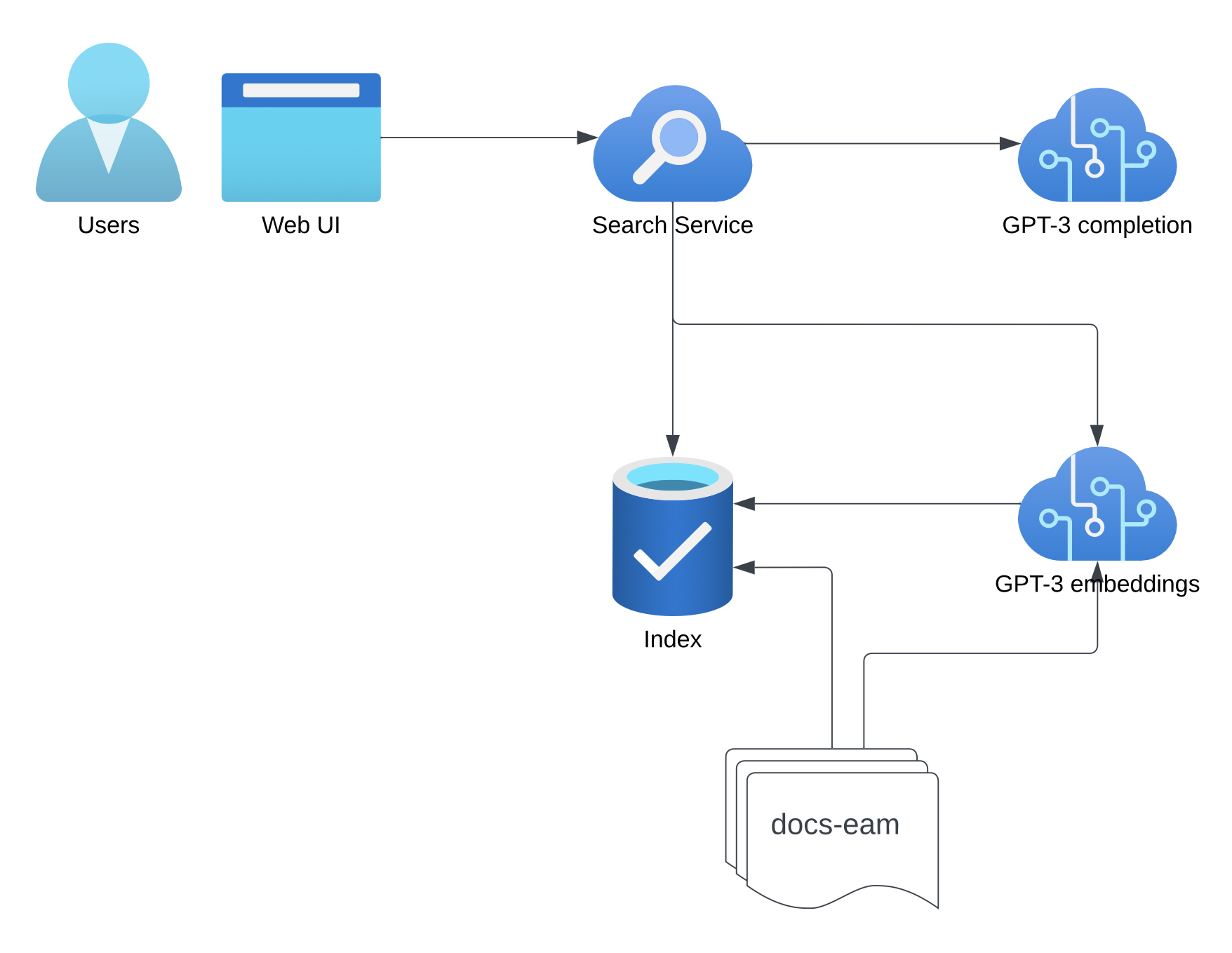
Question Answering with Embeddings
The core technique we used is not novel - here’s OpenAI’s recipe. The problem it’s solving is that context (and thus prompt) size for LLMs (large language models, e.g. GPT-3) is somewhat limited and you cannot add your entire product documentation. You might try to “teach” the model using fine-tuning but that approach is more appropriate for teaching the model new skills, not facts. Instead you break down the problem into two steps: find the relevant documents (or document segments) and then use those in your prompt to LLM to synthesise an answer. This comes with the added benefit of being able to cite your sources and link to relevant documentation pages.
On Embeddings
Embeddings are vector representations of words, phrases, or sentences that capture their semantic meaning. These high-dimensional vectors are generated using pre-trained models, which have been previously trained on large amounts of text data.
The key is that text that talks about similar concepts gets mapped to nearby points in the vector space. Thus embeddings allow us to compare different pieces of text by measuring the similarity between their vector representations.
This also works for comparing the embedding of a query to embeddings of all documents and finding closest neighbours. It will find documents that talk about concepts your query is interested in, implementing a semantic search of sorts.
For example when you embed the string What is a dog? you end up with a vector that is nearby the vector that embeds the contents of a document titled Teach a dog to fetch and relatively far away from embedding for a document titled Cat food. This almost magical property is a result that we’re not just looking at e.g. keywords but using a language model to pull out somewhat more abstract concepts.
Back to the semantic search part; concretely we applied the following approach:
- downloaded an export of our documentation in markdown format
- split up the documents into chunks of max. 1000 token (so we can fit multiple chunks into a single prompt)
- embed all documents and store pairs of embedding vectors and original documents.
- then for each query
- embed the query
- compute cosine distance to all documents (dot product of query vector with each document vector)
- pick the three documents with the closest distance
Answering
The search part already provides us with some links and document chunks that may contain the answer the query. The final step is to try to extract the answer from the found text. For this part we used GPT-3 (a LLM from OpenAI) in completions mode using a prompt that looks something like
{doc 1}
{doc 2}
Using the context above try to answer the following question or answer
"I don't know" if the answer cannot be found in the provided context.
Question: {query}And the LLM does a pretty good job of synthesising the answer. This is a result of a few iterations where we tried to
- Increase number of questions answered correctly (true positives)
- Reduce number of missing answers even though a relevant document was present (false negative)
- Reduce number of hallucinations i.e. factually wrong answers that the model made up (false positives)
The former two points are mostly driven by being able to find and use as much relevant content as possible, while the latter is drastically improved by adding the I don’t know option.
llama-index
Conveniently almost most of the process outlined above is already available as a library called llama-index. It provides tooling to load text documents, create and query embeddings indexes, even integrates with LLMs.
What remains is to prepare and clean the data and provide the prompt.
Evaluating the Prototype
The final step was adding a UI on top of it and deploying to our cluster to get feedback from our customer, documentation and product experts. The standalone prototype was implemented with FastAPI and htmx.
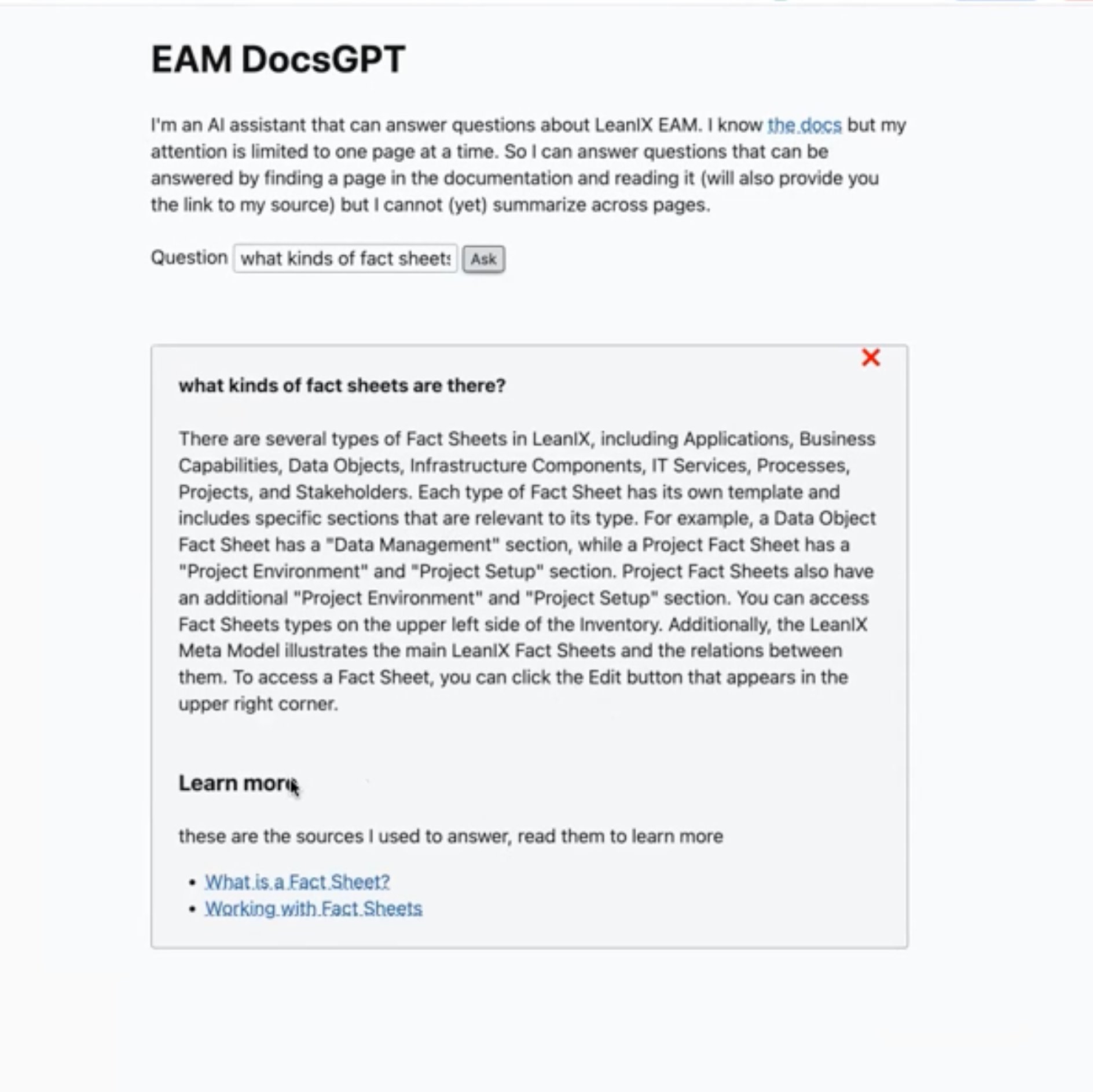
Finally, we evaluated the prototype to assess its performance in answering tool-related questions. We reviewed the AI assistant's responses to onboarding questions to analyse both ability to respond as well as accuracy. Below are the main findings:
The search part did a great job acting as a bridge between natural language and documentation pages, finding relevant pages without knowing the right keywords.
Focusing on answering a single question (no chat or follow up questions) and linking to relevant documentation already provides great value to users.
Bad or misleading answers fell into three categories:
- False Positive: “Hallucinations”, i.e. misleading responses, which is from user-view the more severe one, but potentially can be tuned to rather give no answer than a wrong one
- False Negative: Mistakenly not answering a question even though there is a clear answer in the documentation
- Wrong or missing data in the source documentation in the first place
Documentation only supports the general LeanIX use case:
- Customer-specific: Each customer configures their own data model that may differ significantly from the defaults which are covered in the documentation. Not taking this into account will produce misleading answers.
- User-specific: A user can ask how to perform a specific action but they may not be permitted to execute it.
Not enough interactional support: We found many interactional questions (e.g. “How do I create a Fact Sheet”) that aren’t part of our documentation and therefore not accessible through the assistant. In contrast to conceptual questions (e.g. “What is a fact sheet”)
Conclusion
Through the process of building the AI assistant, we gained valuable insights into the potential of AI technology for product onboarding and enablement. By leveraging GPTs we created a powerful tool that could potentially address the unique challenges our customers are facing.
Within just a few days we’ve built up an understanding of what is possible and what is not easy. However, based on this understanding, we decided not to drive this topic forward - we‘re not launching an AI Assistant for user documentation. We see this as a natural improvement of documentation platforms we use from other SaaS providers and expect such functionality from them in the future.
Published by...

Andraž Bajt
Visit author page