Learnings of implementing an event processor service in an event-driven environment
This article discusses the implementation of an event processor service and the learnings gained by solving multiple typical challenges that can arise when working in an event-driven environment.
Over the past few months, we as a team are working on one of our newer products, called Value Stream Management (VSM), a platform that helps software engineering teams build great products. Recently, we have been focusing on transforming our VSM architecture into an event-driven architecture. To gain deeper insights into how we are implementing event-driven architecture in LeanIX, check out this informative talk by our colleague Per Berhardt on Event Carried State Transfer.
During this process, we encountered several challenges, including race conditions with parallel processing of events and scalability issues with event processing. While it was not easy to resolve these problems, the learning opportunities we gained through this process were extremely valuable.
To provide some background, we are developing a microservice that calculates engineering metrics by consuming data from various sources. This is a Spring Boot application that uses different Azure Event Hubs to consume data and a Postgres database to store calculated metrics and serve as an event store.
The following paragraphs will provide context on our tech stack and how it brings benefits to an event driven environment.
Event Store
An event store is a database that is specifically designed to store events in a way that allows you to track the current state of the system and replay events to restore the final state in case of issues. This can be useful for a variety of purposes, such as enabling time-travel debugging in software or implementing event-driven architectures in which microservices communicate with each other by sharing events.
There are several advantages to using an event store:
Persistence: An event store provides a permanent record of events, which can be useful for tracking changes over time and auditing purposes.
Scalability: An event store can handle a large number of events and support high-throughput scenarios, such as real-time event processing. By using parallel processing, we will be able to achieve greater scalability in the future.
Flexibility: An event store allows you to decouple the production of events from the consumption of events, which makes it easier to add new consumers or producers without affecting the existing system.
Event replay: An event store allows you to replay events for testing, debugging, developing new features, and recreating a state after outages or other corrupted data issues.
Using non-blocking I/O with Event Hub can also provide several benefits when using an event store. Since Event Hub is not blocked waiting for a response from a client, it can continue to process other requests and maintain high availability. This can help to ensure that your event store remains available and responsive even in the face of failures or performance issues with individual clients.
Event Processing
An event processor is a component of an event-driven architecture that is responsible for reading events from the event store and processing them according to specific rules or logic. It typically reads data from the event store on a scheduled basis or with a trigger and performs tasks such as filtering, enriching, and transforming the events as they are consumed.
Initial Architecture of async parallel processing
One of the main advantages of having an event-driven architecture and working with Event Hubs is that there is already a high level of performance through concurrency and parallel processing on the event consuming side available out of the box. For our microservice, we wanted to ensure that we can leverage this parallel processing paradigm to have a very performant service throughout the whole data stream. Our initial architecture had event processors that would process events saved in our event store asynchronously as soon as a new event arrived. We saved the event in the event store and triggered an async flow via the consumer client to process it. The consumer client initiates the async flow. However, we encountered several issues with this approach, the most obvious of which was a race condition.
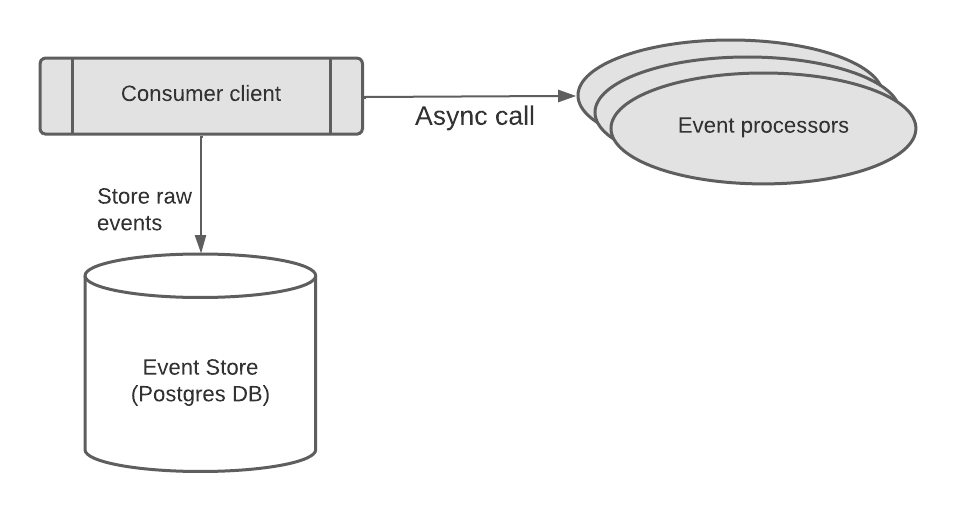
Consider two events arriving at almost the same time, with only a few milliseconds of difference between them, one for creating User A and one for deleting User A. These events are related, and the order in which they are processed is important. If both events are processed by different processors simultaneously, there is a risk of a race condition. For example, if both events contain data that needs to be updated in the same database record, and both processors try to update the record at the same time, it could lead to data inconsistencies or corruption.
Reverting to single lane processing
To address the issue of race conditions, we decided to stop using parallel processing and instead introduce a single processor pod in Kubernetes that runs on a scheduled basis. This processor reads data from the event store in order and processes it one event at a time. Because the events are processed in order, we no longer have to worry about race conditions. It's worth noting that the event store maintains the order of incoming messages for each customer, as the customer id is used as the partition key in Event Hub.
Event Store table partitioning
Introducing a single processor pod resolved our race condition issue, but we already knew that this solution would not be scalable enough for our future architecture. As we start having more and more load in the system, it will produce too much latency to process all incoming events using a single processor. It was clear that we needed to find a way to make parallel processing work for us. In order to make our event processing more responsive, we had to start scaling processors in a way that each processor will focus on their own Event Hub partition ranges without overlapping with others. That way, since ordering is preserved at Event Hub partition level, having parallel processing made perfect sense for us.
To implement this new processing mechanism, we initially considered using partitioning on our event store. This would allow consumers to deliver incoming events to the corresponding partition using a consistent hash function. Theoretically, it made sense for us to rely on Postgres Table Partitioning, so we prepared a proof of concept to see if our solution was viable.
Consistent Hashing
We needed to find a way to evenly distribute incoming events across the different table partitions when implementing partitioning on our event store. It was important that events with the same customer id always went to the same partition, so that our processing mechanism could continue to operate in the same way as it did in the single processor scenario. We looked into different methods of achieving this, the most promising and common one used in this case is consistent hashing.
In consistent hashing, a hash function is used to map keys to a range of integers, and each node is assigned a range of integers that it is responsible for. When a new key is added to the system, it is hashed and the resulting integer is used to determine which partition is responsible for storing it. If a partition is added or removed from the system, only a small number of keys need to be moved to new nodes, as each node is only responsible for a narrow range of integers.
In our scenario the keys are the customer id on each incoming event and this algorithm would then map the id to the correct partition and the event would be saved there.
The issue with this approach is that this logic only works as long as it is running on the same instance and there is no interruption that requires a restart of the application. Also while testing different algorithms the results were quite inconsistent in terms of correct mappings. To combat this, we would have to add a hash table to our database that keeps track of the customer ids and the partition that they are saved on and deal with the case where we might want to change the number of partitions on the table. This would create additional complexity and the risk of production data being corrupted or misplaced in the partitions was too large so we ended up abandoning this idea. This is the reason why we chose an alternative solution without partitioning.
Solution
Background
Consumers can specify which partition they want to read from when connecting to an Event Hub. This allows multiple consumers to read from different partitions in parallel, providing balanced access to the data stream and enabling higher throughput. For our particular service we can therefore leverage this parallelism for our event consumer out of the box. For our event processing we want to use a similar approach to implement parallel processing and improve performance, but we want to avoid the implementation and complexity cost of actually applying partitioning on our own event store. To achieve this we split our event processing application into multiple pods and each pod will be responsible for a range of partitionIDs. The partitionId for each event will be read from the column in the event store. Therefore we can still keep one table but split the processing work between the different pods.
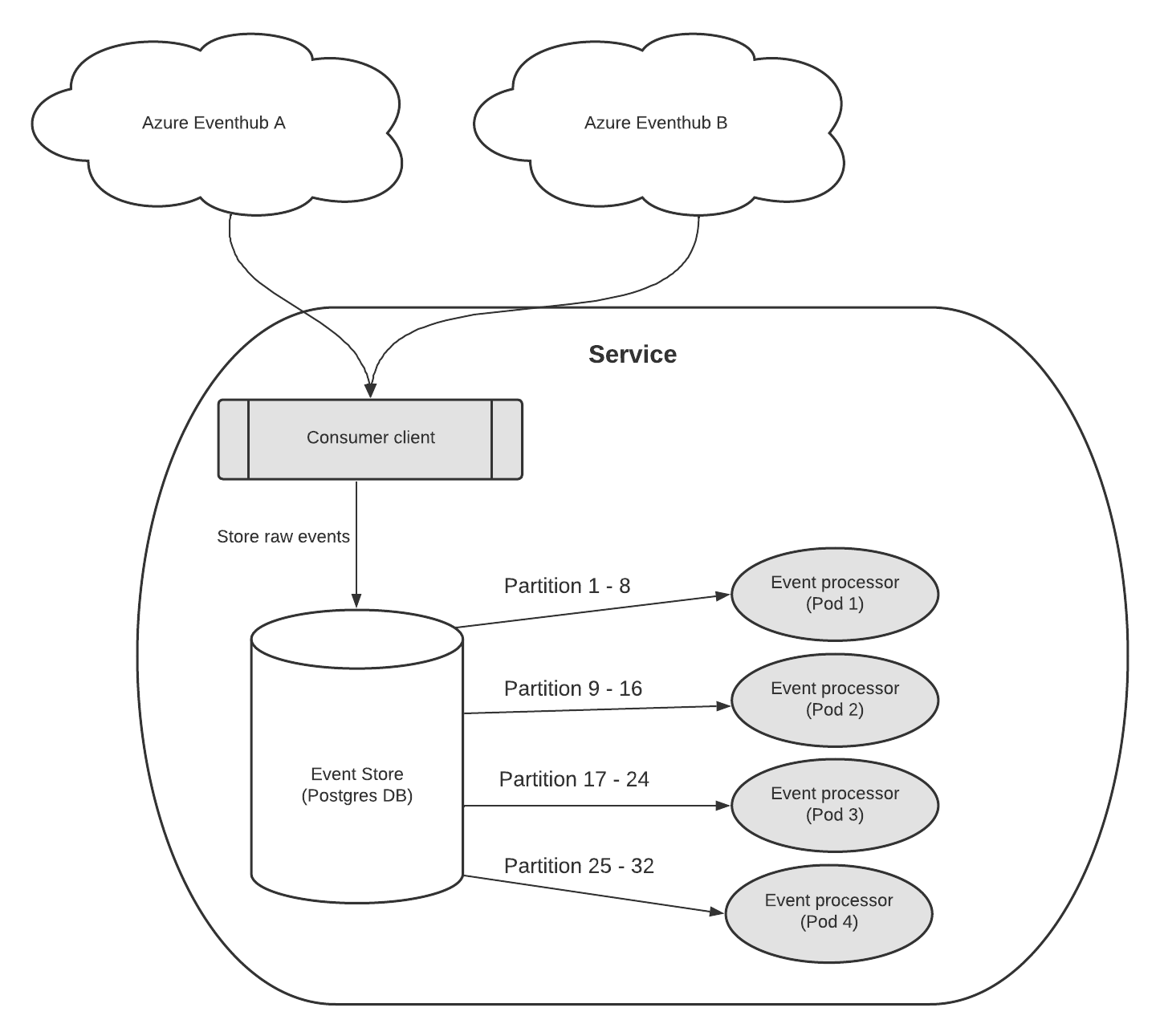
Implementation
In LeanIX specific use case we are using the Azure Event Hub.
The Event Hub applies partitioning to the events it provides. These events are split into 32 partitions, and each partition provides a set of events for consumption by the event consumer. The partition ID is included in the event payload, allowing a set number of event processing pods to consistently and evenly assign partition IDs to specific pods.
A Postgres database is used as an event store where the raw events are stored after initial consumption. The partition id is being stored in a column, to be accessed later for processing.
To implement this approach, it is important to maintain a consistent number of partitions, which in this case is 32. The number of pods should ideally be an evenly divisible number of that total. For example, in the described implementation, 4 pods were used, but any number is theoretically possible. However, using a number that is not evenly divisible may result in an uneven distribution of data across the partitions.
To assign relevant events to each pod, an event processing function retrieves all relevant events based on the partition ID range for that particular pod and processes these events. A utility function calculates the partition ID range for each pod using the pod number, which is passed as a Kubernetes environment variable to the Spring Boot application and retrieved from the application properties.
For this a Kotlin extension might be used, that calculates the partitionId range based on the pod number like so:
// for this basic algorithm you are expected to select exactly divisible numbers
val amountOfEventHubPartitions = 32
val amountOfActivePods = 4
fun Int.calculatePartitionRange(): Pair<Int, Int> {
val partitionRange = amountOfEventHubPartitions / amountOfActivePods
val start = (this - 1) * partitionRange + 1
val end = start + partitionRange - 1
return Pair(start, end)
}As the input we need the podNumber, which we can pass as a Kubernetes evironment variable to our springboot application.
Kubernetes deployment yaml:
env:
- name: POD_NUMBER
value: "1"Spring Boot application.yaml:
application:
pod-number: ${POD_NUMBER}By then passing this pod number to the Application properties we can call it to retrieve the partitionId range like so:
val range = applicationProperties.podNumber.toInt().calculatePartitionRange()Once the partition ID range for the current pod has been determined, a repository class with a specific query is used to retrieve the raw events to be processed.
@Repositoryinterface EventStoreRepository: JpaRepository<EventStoreEntity, UUID> {
@Query(value = "SELECT es FROM event_store es WHERE es.partitionId BETWEEN >= :start AND :end")
fun findAllByRange(start: Int, end: Int, pageable: Pageable): List<EventStoreEntity>
}This query returns all events with partition IDs within the range relevant to the current pod. To improve query performance we can use indexing on the partition ids and that way, index scan will be done since b-tree is default indexing strategy of Postgres.
val events = eventStoreRepository.findAllByRange(range.first, range.second)Finally, the retrieved events are processed as needed.
This fake partitioning approach allows for the distribution of event processing across multiple pods and an even distribution of the workload, improving the performance and scalability of the event processor application.
Conclusion
In conclusion, adopting an event-driven architecture brings several benefits to our system, including enhanced data persistence, scalability, and flexibility. However, it also comes with its own set of challenges that require a thorough understanding of the underlying technologies and a significant investment of time and resources. Performance is a key consideration in event-driven architectures, which handle high volumes of data, and it is important to carefully design and implement the system to make the most of the event structure.
In our case, we encountered issues with race conditions and scalability in our event processors. By implementing a new architecture using multiple event processors in parallel with the Event Hub partitions, we were able to overcome these challenges and improve the overall performance of our system.
Going forward, we will continue to optimise the performance of our event-driven architecture to meet the needs of our system and users. The insights and lessons we have gained through this process will be valuable as we continue to evolve and improve our system.
Published by...

Alper Cezibarak
Visit author page

Tim Meyer
Visit author page