Scaling Infrastructure Provisioning
Finding the balance between team autonomy and having an infrastructure team is hard. This post shares our approach to having a dedicated infrastructure team, while enabling product engineering teams to quickly provision their required infrastructure via a simple API.
Over 650 customers worldwide rely on LeanIX to manage the transformation and risk of their IT landscape. To satisfy the diverse requirements of such a large number of customers, LeanIX's engineering department has grown to over 20 teams at the point of writing this post. Each team is accountable for their respective domain. Like a lot of larger software companies today, LeanIX relies on a microservice architecture to cope with the scale of our products. A complex distributed system like this, requires a large amount of well configured infrastructure to guarantee a smooth experience for all our customers.
Who is Responsible for the Infrastructure?
The cloud infrastructure needed to run our complex system is part of a larger entity that we want to call the "platform". More general, Evan Bottcher describes the characteristics of a platform as:
An operating environment which teams can build upon to deliver product features at a higher pace, with reduced co-ordination.
At LeanIX a platform tribe provides the internal services that make up our platform to the product engineering teams. This helps with iterating quickly over the internal services and reduces cognitive load, that would be required by the product engineering teams to develop these internal services themselves. However, it couples the product engineering teams to the platform teams.
Solving an Organizational Challenge with Software
The best way to maintain a good platform is to make it accessible to the product engineering teams, via a simple to use self-service API. This allows product engineering teams to profit from having a platform, while they are still able to independently provision infrastructure for their services. In the following, I want to present the opinionated approach taken by LeanIX to provide and implement such a self-service API.
Complexity of a Single Service's Infrastructure
At LeanIX, a typical microservice's infrastructure consists of resources to run the service in a Kubernetes cluster, persistence related resources, monitoring resources, and resources to access our internal event streaming API.
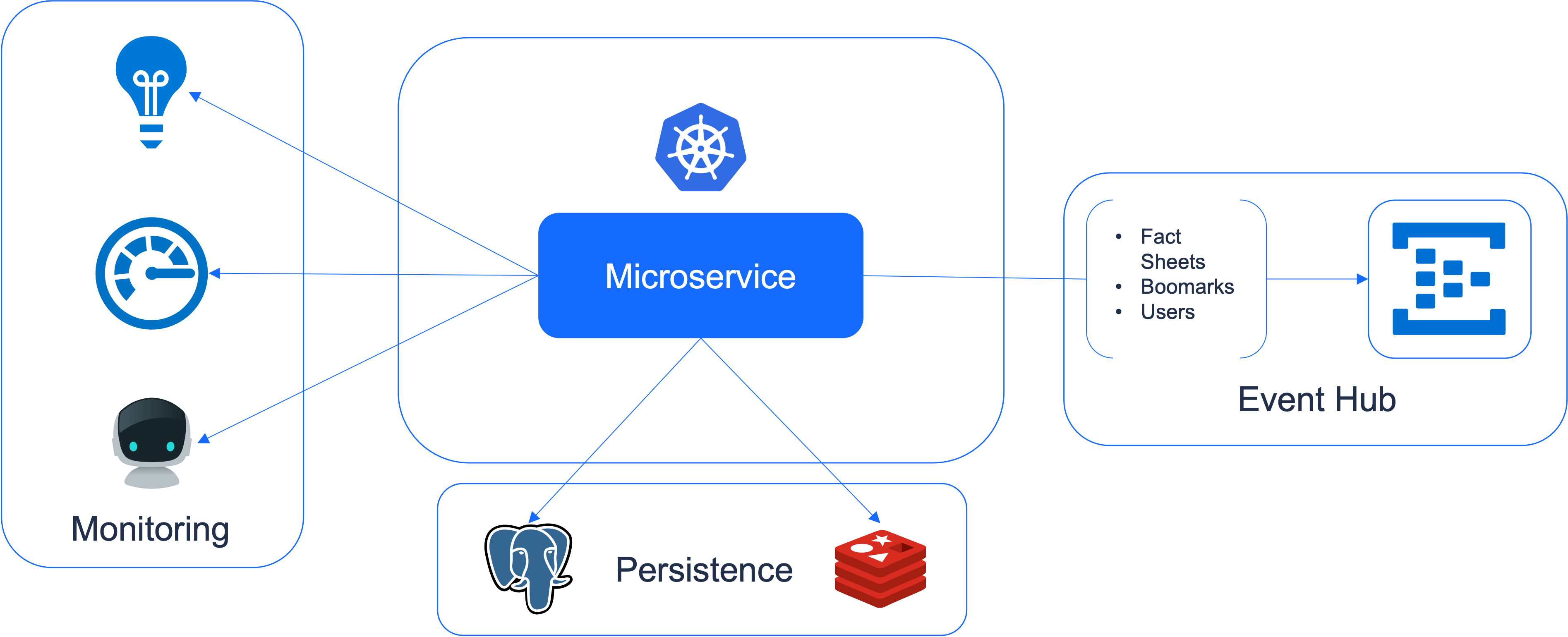
Furthermore, LeanIX runs its systems in different parts of the world, in order to guarantee great performance for all customers. This means a single services infrastructure must be replicated for different regions and environments.

In total we will have to setup the service's infrastructure on six regions and multiple environments before the product team may deploy their first version.
The Goal
Considering the above described complexity, the following holds true for a scalable system for infrastructure provisioning:
- Product teams are able to request infrastructure via a single pull request, without having to communicate with the infrastructure organization.
- Product teams only need to know the high level view on their service's infrastructure. For example, they would only need to specify that they require a Postgres database and some monitoring tools.
- The complexity of having multiple regions and environments should be hidden from the product teams.
- Provisioning of actual infrastructure is critical, and thus should be controlled and only approved by the infrastructure organization.
- Infrastructure engineers should have to do the least possible amount of manual work to provision a service's infrastructure.
We call our self-service API "Service Environments". It provides an easy to use interface to product teams, through which they can define their service's infrastructure. The provisioning of all concrete resources is then handled through automation.
Implementation
In the following, we provide an example for a service's definition using our self-service API.
name: notifications
team: atlas
kubernetes: true
postgres:
enabled: true
extensions:
- uuid-ossp
distribution: regional
event:
consumer:
pathfinder-api:
- fact-sheets
- bookmarks
- comments
mtm:
- users
surveys:
- surveys
todo:
- todos
applicationInsights: trueThis file defines the notifications service as using the following parts of our platform:
- The service runs on Kubernetes.
- The service requires a Postgres database with the uuid-ossp extension enabled.
- The service should be available on all regions supported by LeanIX.
- The service consumes events from a variety of other services at LeanIX.
- For monitoring, the service uses Azure Application Insights.
The service definition lives inside a single git repository. The Terraform code for the actual components, like the Postgres database is all maintained in dedicated repositories. Splitting the infrastructure components into small independent building blocks, allows us to have automation around the self-service API, as well as quickly iterate on the building blocks themselves.
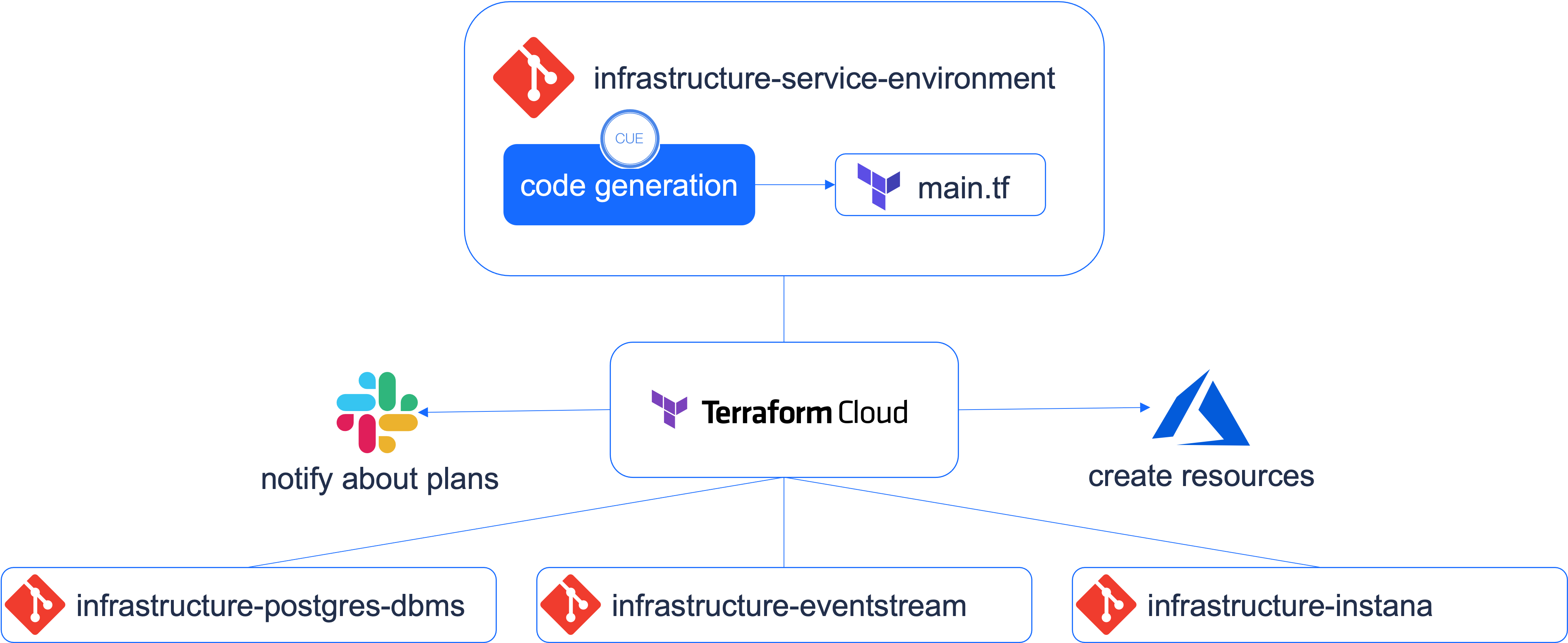
The image above illustrates the complete automation workflow around our self-service API "Service Environments".
- The team's service definitions are enriched through code generation with information concerning the complexity of our infrastructure.
- Once a PR is merged that adds / modifies a service definition, our central automation hub Terraform Cloud is triggered.
- Terraform Cloud will plan the generated Terraform code for infrastructure-service-environments.
- Slack will now trigger a notification to the platform tribe, requesting an apply of the plan.
- Applying the plan triggers the planning of our smaller infrastructure building blocks. For example infrastructure-postgres-dbms might need a replan in order to add the resources necessary for a new Postgres database.
- The infrastructure tribe receives notifications about each infrastructure repository that would create new resources as a result of a modified / added service definition. Manual approval is required in all cases.
Conclusion
Through using Terraform Cloud as our central way of rolling out new infrastructure and by cleanly separating different parts of the infrastructure in their own repositories, we were able to mostly automate the provisioning of infrastructure at LeanIX. As a result, we have reduced team dependencies and can effectively maintain an infrastructure organization as a sub-part of the whole engineering organization. This allows us to save resources, build up expertise in specific areas, and deliver software faster from within each team.

Published by Yannick Epstein
Visit author page