How to arrange GitHub actions to improve feedback cycles
Learn how one of our engineering teams reorganized their GitHub workflow to improve their developer experience. The main focus was to separate concerns, reuse Docker test containers, and shard tests for parallel execution.
TL;DR
The key takeaways include reorganizing the GitHub workflow to separate concerns, reusing test containers, and sharding tests for parallel execution. These actions resulted in a significant reduction in test execution time and faster feedback cycles.
Situation
Our teams' Node.js backend follows a simple GitHub workflow consisting of two jobs: Build and Deploy. When a pull request (PR) is made, the Build job runs tests and builds the application. After the PR is merged, the workflow runs again with an additional job, which deploys the app to the production environment. Despite the simplicity of the workflow, the jobs can be time-consuming, taking an average of 28 minutes. The Build job, in particular, accounts for approximately 85% of the total time.
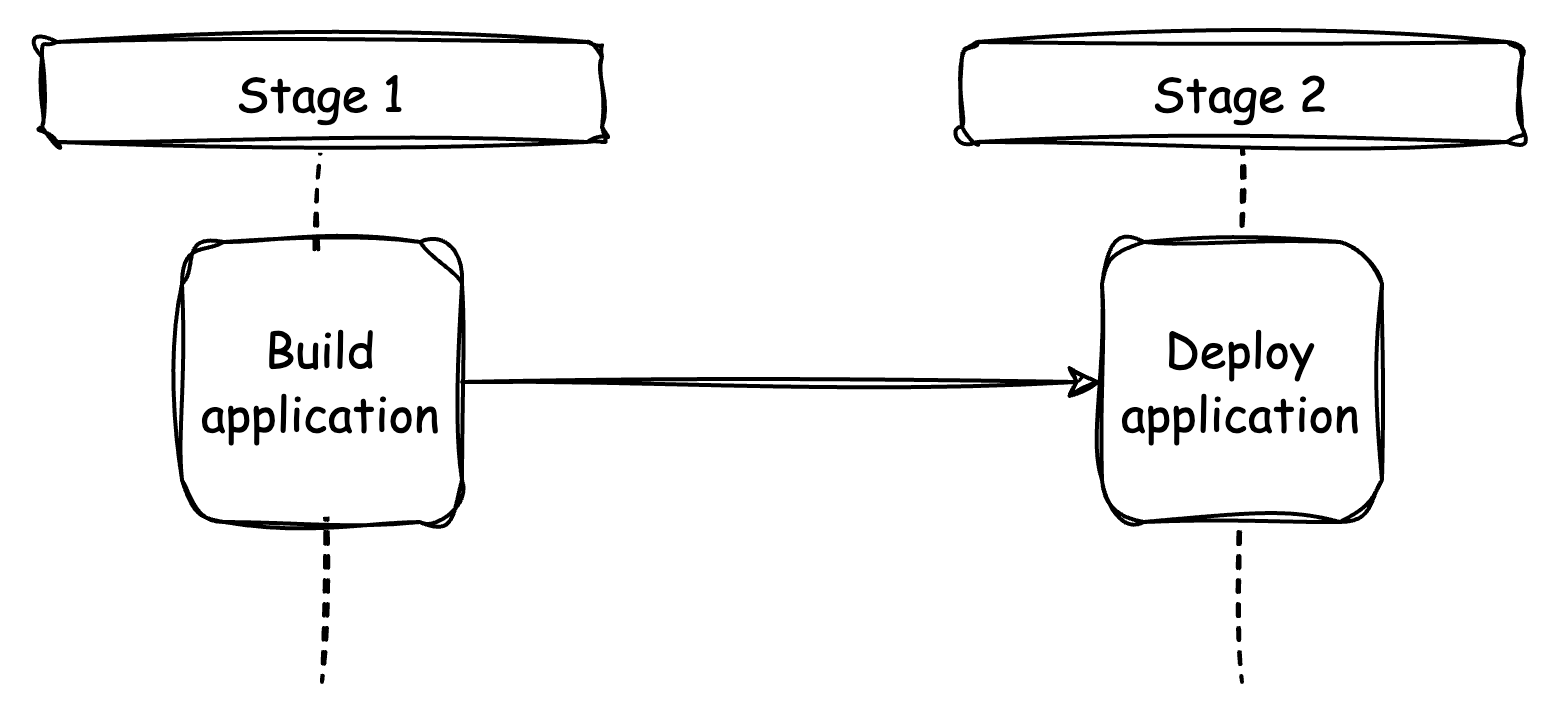
| Stage 1 | Stage 2 | Total | |
|---|---|---|---|
| Time taken | ~ 23m | ~ 4m | ~ 27m |
Waiting for more than 20 minutes for CI to confirm the validity and readiness of your change is incredibly frustrating. This prolonged wait time significantly delays the regular development workflow, which involves preparing a PR, requesting a review, reviewing, and addressing any review comments. The substantial gaps between taking action and seeing results often lead to the temptation of starting another task. However, switching contexts can have a significant impact on productivity.
Additionally, the repository receives contributions from colleagues in other teams who make infrastructure-related changes. When they have to wait for more than 20 minutes for the CI to validate the changes, it not only wastes their time but also reflects poorly on us as a team responsible for the workflow.
Tasks
The goal is to improve the efficiency of CI runtime for tests, builds, and deployment to receive faster feedback. However, we have identified some deficiencies that we need to address to achieve this goal.
- The workflow lacks separation of concerns. The Build job performs all steps except those needed for deployment, making it difficult to quickly identify failed steps.
- Tests consist of a combination of unit and integration tests. For integration tests, the Testcontainers library is used to create a PostgreSQL database using Docker for each test suite.
- Since the tests are running with the
-runInBandoption, they will not make use of all the available workers within the CI environment.
Actions
Now we have identified the shortcomings, what actions can we take to overcome them?
- Reuse the PostgreSQL docker container.
- Arrange the jobs.
- Run tests in parallel on different machines (sharding).
Good, now let's look at the individual actions.
Reuse test containers
While running the tests, we found out that we were creating a new PostgreSQL Docker container for every test. We weren't aware of container reusability because we have been using an older version of Testcontainers.
One could argue that achieving the same result as the previous setup, designed for test isolation, is possible by populating and truncating the respective tables before and after each test.
We fixed this in 2 stages:
Stage 1: Adapting tests to reuse containers
The first step towards reusing containers is to modify the test so that different tests can use the same database without interfering. The challenges here revolve around ensuring data integrity and isolation across tests.
The solution lies in careful database setup and teardown. We need to ensure that the database is in a pristine state before the test runs. Like many others, we cleaned the database after a test run. This is not optimal because failed tests could leave traces in the database, which would affect later tests. Therefore, we moved the table cleaning to beforeEach method.
// truncate happens within afterEach
beforeEach(async () => {
await setUpDatabase();
await pg.table("tableName").insert(entries);
});
afterEach(async () => {
await pg.table("tableName").truncate();
});
// truncate happens within beforeEach
beforeEach(async () => {
await setUpDatabase();
await pg.table("tableName").truncate();
await pg.table("tableName").insert(entries);
});So, even if any of the previous tests fail, we can be sure a test always starts with a clean slate.
Now that we can be sure that every test starts with a pristine database, we can use the Testcontainers library's withReuse option. This option will reuse the database container between the tests instead of spawning a new one.
export async function setupDatabase(): Promise<void> {
const container = await new GenericContainer('postgres:11.5')
.withExposedPorts(5432)
.withReuse()
.start();
}The improvements from this step are significant. Not only do we save the time it takes to start up and destroy a container, but we also reduce the load on the system, which leads to more stable and reliable tests.
npm test before | npm test after | |
|---|---|---|
| Time taken | ~ 221s | ~ 90s |
Stage 2: Moving database setup to global setup/teardown
As you can see, we run the database setup in every beforeEach method. Even with withReuse() functionality offered by the Testcontainers library it takes some amount of time to run. To speed up the tests, we moved the database setup to a global setup and teardown stage. This involves creating and destroying the database container only once for the entire test suite, rather than for each test.
In Jest, a JavaScript testing framework, you can do it using the globalSetup and globalTeardown configuration options. Here's an example:
// jest.config.js
module.exports = {
globalSetup: './jest-setup.js',
globalTeardown: './jest-teardown.js'
}
// jest-setup.js
module.exports = async function() {
const container = await new GenericContainer('postgres:11.5')
.withExposedPorts(5432)
.withReuse()
.start()
process.env.POSTGRES_PORT = String(container.getMappedPort(5432))
process.env.POSTGRES_HOST = container.getHost()
globalThis.container = container
}
// jest-teardown.js
module.exports = async function(): Promise<StoppedTestContainer> {
const global = (globalThis as unknown) as Global
return await global.container.stop()
}In this example, we are starting a Postgres container in the global setup stage and storing a reference to it in the global scope. All tests in all suites will reuse the container, which significantly reduces the time it takes to run them.
npm test before | npm test after | |
|---|---|---|
| Time taken | ~ 90s | ~ 50s |
By reusing containers, we sacrificed strict test isolation in favor of faster test runs and improved feedback cycles. This tradeoff has been worth it thus far.
Arrange jobs and steps
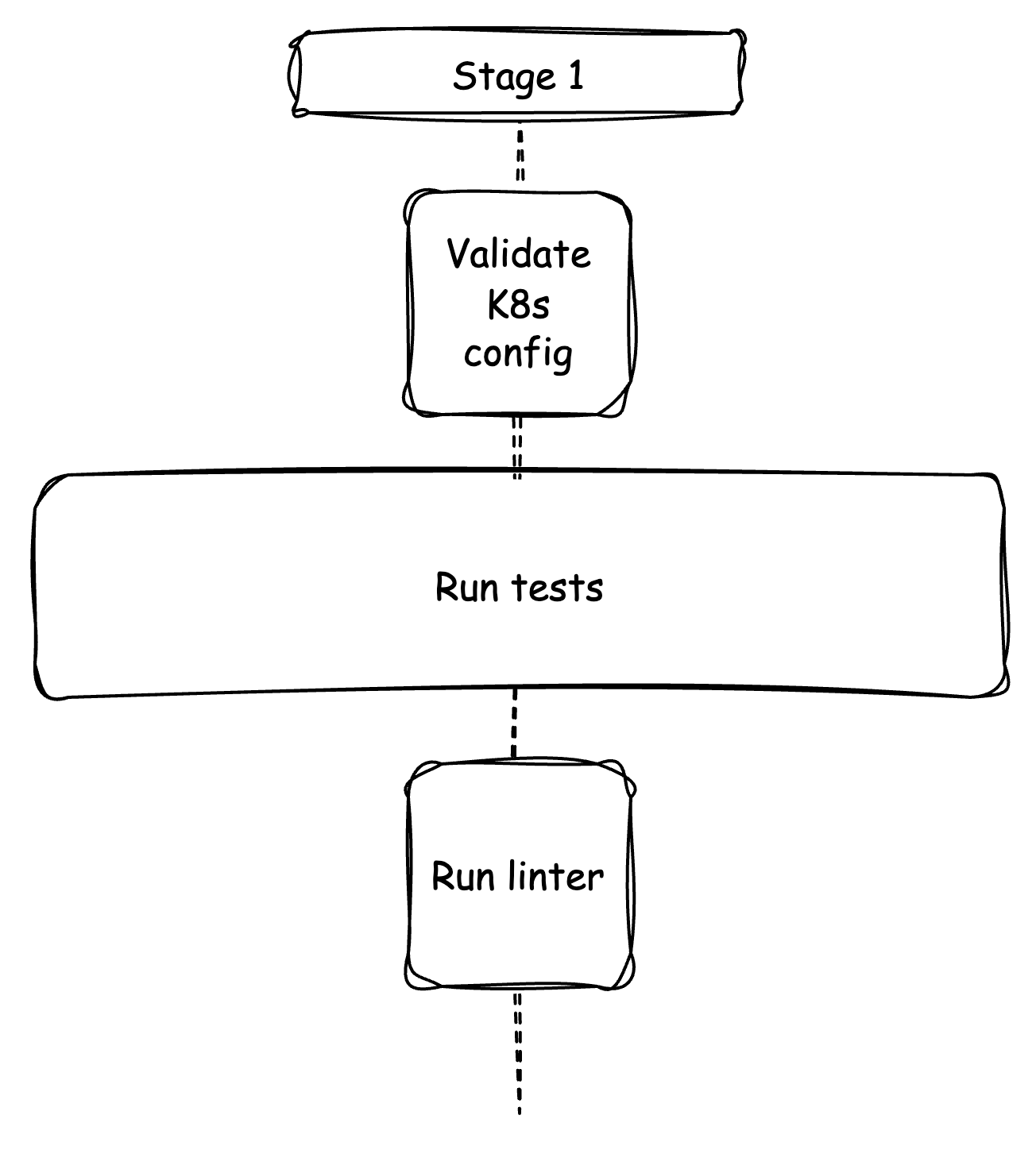
After analyzing the GitHub workflow, we discovered that the Build job includes a variety of steps, such as:
- Running tests
- Validating test coverage
- Linting the code base
- Validating the k8s deployment config
- Building the application
- Deploying the application
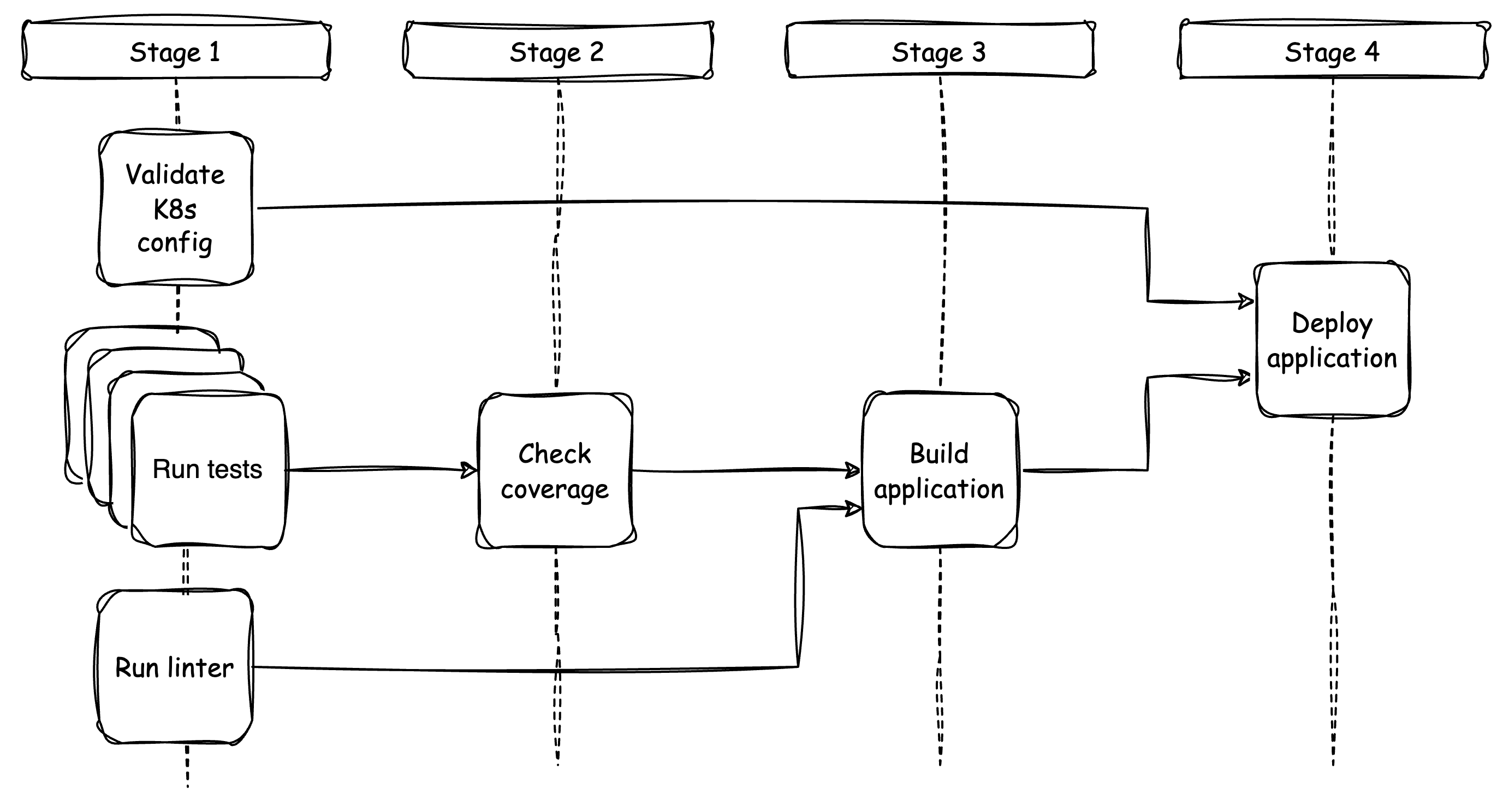
Reorganizing the steps and splitting them into dedicated jobs and different stages reveals a better picture of the work that is actually done within the workflow.
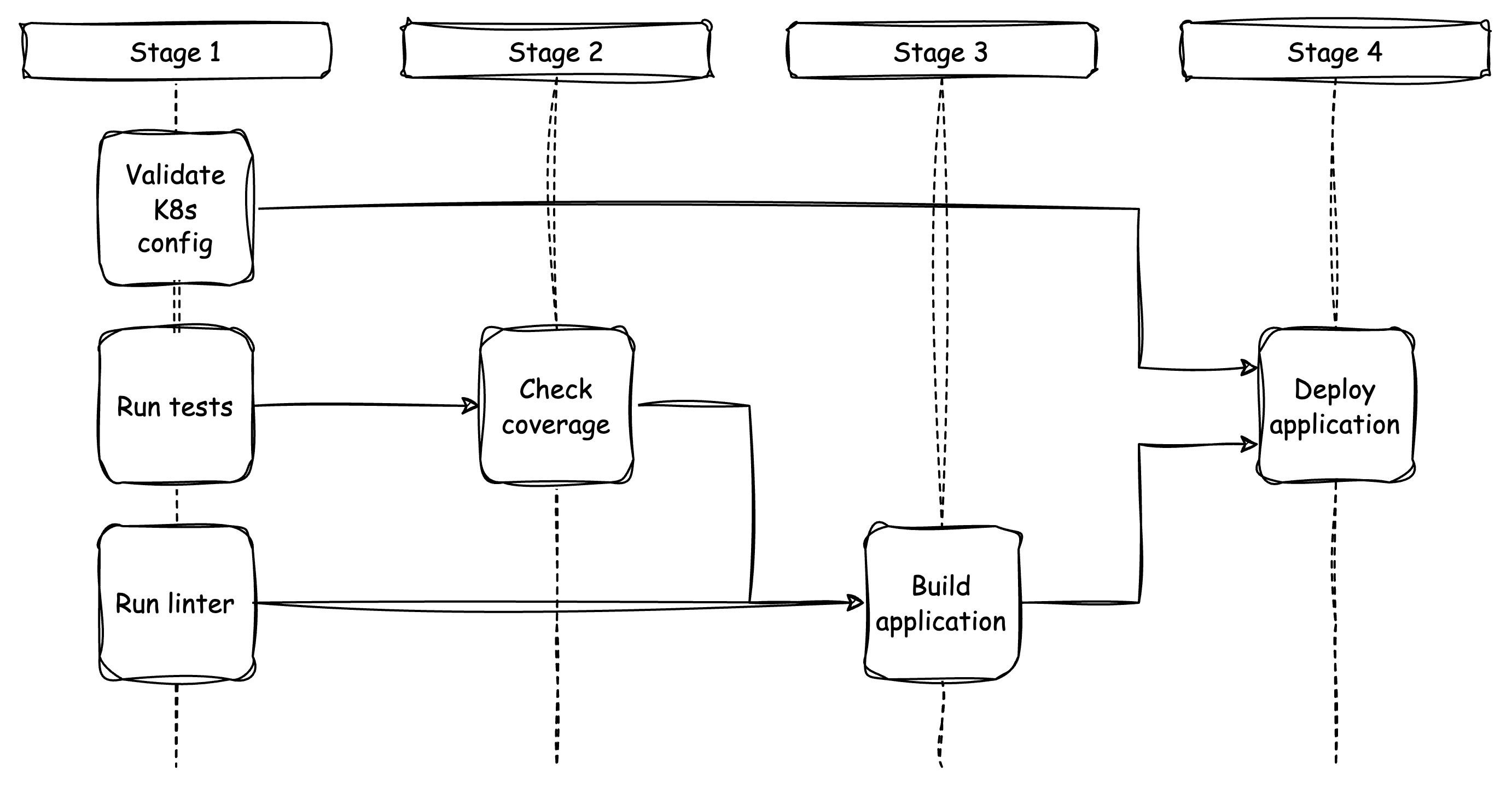
Organizing the workflow into stages is a helpful way to manage jobs and their steps. All jobs within a stage can run in parallel as they do not depend on each other. However, jobs in different stages have dependencies and require sequential execution.
From the picture above, it is evident that CI provides quick feedback on test results. The testing jobs run simultaneously, while the application building job is deferred.
Please note that distributing steps across different jobs increases billable minutes because certain tasks, such as preparing the Node.js environment, are repeated. However, we accept this tradeoff for a more efficient and modular setup.
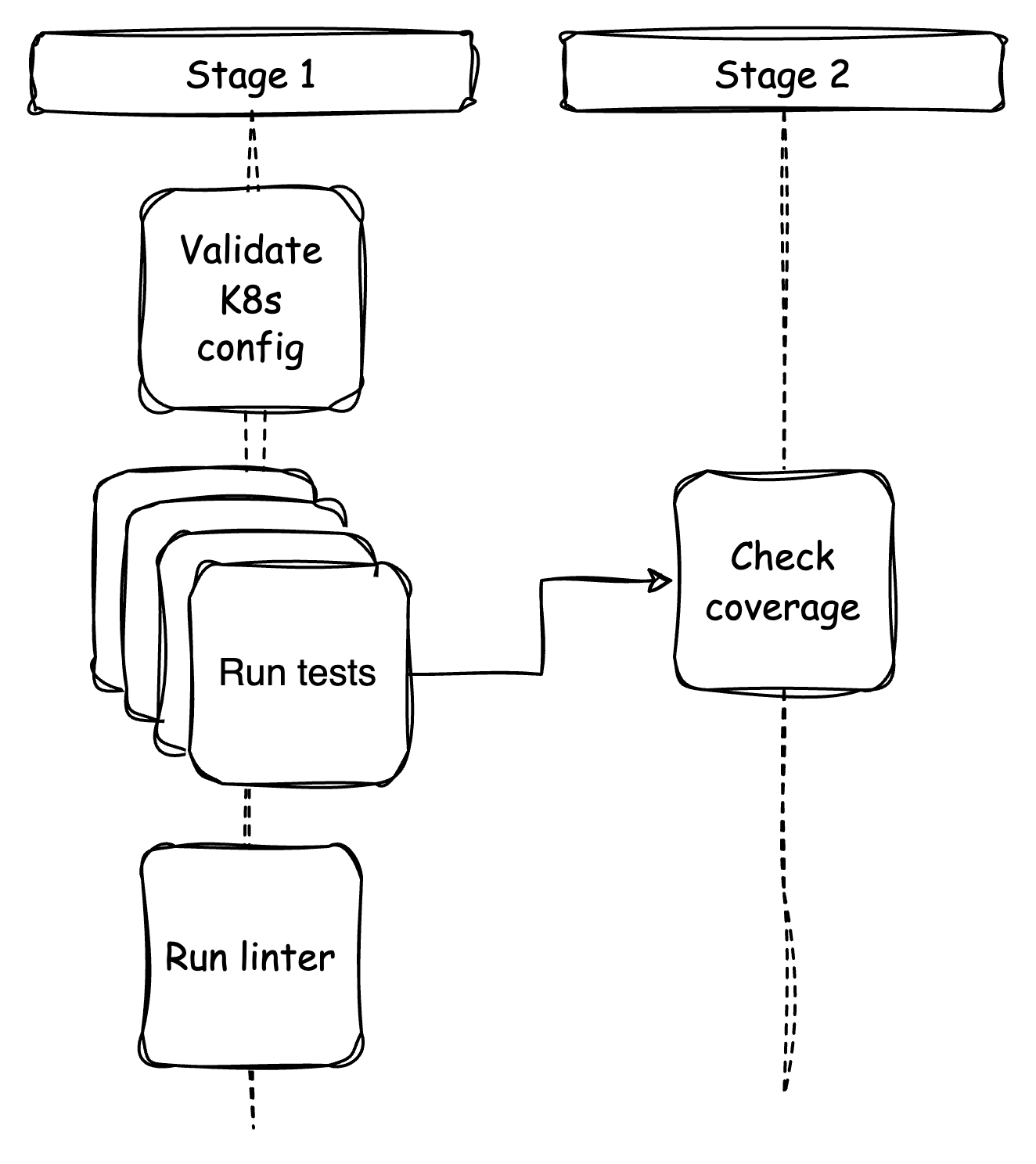
Shard the tests
After separating out the different jobs in the previous step, it becomes clear that the time it takes for the tests to complete is now the limiting factor.
Even after optimizing the integration of Testcontainers, tests still take more than 10 minutes until the continuous integration (CI) publishes the final test results.
Jest provides the maxWorkers option for running tests with multiple worker threads on the same machine. However, in this project's specific situation where there is no clear correlation between test files and the tables they use, running tests with different workers could result in interference and unpredictable outcomes. Therefore, we prefer to run the tests using the runInBand option. This is especially prudent since the GitHub workers are shared machines with limited resources.
Since version 28, Jest supports the -shard command line option, which allows us to define a GitHub matrix to split the work of the Test job into shards. Dedicated GitHub workers are used to execute each shard, enabling independent execution of the tests. However, it is important to consider that each GitHub worker adds additional overhead. Therefore, finding the right balance between the added overhead and the time saved by using different GitHub workers is crucial.
In our project, it takes approximately 30 seconds to prepare the test environment. We set up the Node.js environment by using the cached node_modules folder and running npm ci. Creating four shards will increase the billable minutes for the updated workflow by 2. We accept this tradeoff for now to receive feedback more quickly, similar to when we re-arranged the jobs.
Now, let's get started and see how we can set up the GitHub workflow to make it happen.
First, we define a simple single dimension matrix that enables us to use four workers for running the tests.
strategy:
matrix:
shard: [1, 2, 3, 4]Once the matrix is defined, we need to instruct Jest on what to do using the -shard option. It requires a value in the format of n/m, where n represents the current shard and m represents the total number of shards. For example, -shard=1/4.
- name: Run tests
run: |
npm run jest -- \
--runInBand \
--collectCoverage \
--coverageReporters json \
--shard=${ { matrix.shard } }/${ { strategy.job-total } }Now, let's turn the attention to test coverage. Since we have distributed the tests among four workers, we need to gather the coverage data from each worker. This means we have to wait for all workers to finish. To address this, we have placed the coverage job in the second stage, which depends on the successful completion of all test jobs. The instabuljs/nyc library reads the four coverage files and generates a combined report. It also checks the coverage numbers against the thresholds we have defined.
Okay, let's configure it.
First, rename the final file to indicate its source worker, and then zip it to save space.
- name: Rename coverage file
run: |
mv \
coverage/coverage-final.json \
coverage/${ { matrix.shard } }-${ { strategy.job-total } }.json
- name: Zip coverage file
run: |
gzip coverage/*.jsonNext, we use GitHub's artifact storage with the shortest retention time to store the coverage file for the next job. This approach is the only method for transferring outputs from one job to another.
- name: Upload test results
uses: actions/upload-artifact@v3
with:
name: coverage-artifacts
path: coverage/
retention-days: 1Finally, we can download all the coverage files created by the test workers and uncompress them. The command npx nyc report is used to print a coverage report to the console, while npx nyc check-coverage checks the coverage numbers against the thresholds set in package.json.
- name: Download coverage data
uses: actions/download-artifact@v3
with:
name: coverage-artifacts
path: coverage/
- name: Unzip code coverage
run: |
gzip -d coverage/*gz
- name: Check code coverage
run: |
npx nyc report --reporter=text
npx nyc check-coverageResults
| Stage 1 | Stage 2 | Stage 3 | Stage 4 | Total | |
|---|---|---|---|---|---|
| Time taken | ~ 3m | ~ 30s | ~ 2m | ~ 4m | ~ 9m 30s |
The reduction in billable time is minimal, but it was not the goal anyway. The time saved by modifying the usage of the Testcontainers library is now allocated to the overhead of setting up multiple worker machines. That's good!
The time to receive feedback from CI has been significantly reduced. It used to take more than 20 minutes before the change, but now it takes around 3 minutes. That's great!
Changing the way we integrate Testcontainers into our project resulted in a significant reduction of approximately 75% in local test execution time. We did not aim for this improvement, but it is substantial!
Conclusion
Here are the key takeaways:
- Separate the concerns. If you are testing something, name it "test" and only include tests. If you need to build something, name it "build" and include the steps to build the artifacts.
- Create a test strategy based on the well-known testing pyramid to limit the number of expensive tests. Create unit tests to test different code branches, and use integration tests to validate that the units work together. Remember, the happy path is enough for integration tests. Edge cases and variations of input data can be easily handled within unit tests. However, the happy path can include error cases that are propagated outside of the system.
- Start taking action early when you notice problems before they become obstacles in your daily processes.
- Stay updated on the latest developments. Some of your problems may have already been solved by other developers. Leverage the power of collaboration.
- Make small improvements continuously.
Thank you for reading until the end.
Resources
- GitHub Docs - Understanding GitHub Actions
- Testcontainers for Node.js - Reusing a container
- JEST - globalSetup
- JEST - globalTeardown
- JEST - CLI #shard
- GitHub Docs - Using a matrix for your jobs
- istanbuljs/nyc - merge
Published by...

Aritra Mondal
Visit author page

Joerg Fiedler
Visit author page