PostgreSQL Index Creation - How it works
Understand index creation in PostgreSQL, and how to decide how to build it.
This blog provides a short overview of index creation in PostgreSQL and tries to give some insights what to take into consideration how to built it.
The CREATE INDEX documentation is the best starting point to understand how index creation works. Nevertheless, I tried to point out the most important information in this blog post. Therefore, I will not write down all possible parameters, as they can be looked up in the documentation easily.
Index Types
PostgreSQL provides the following types: B-tree, hash, GiST, SP-GiST, GIN, and BRIN
The default index is B-tree and for most default use cases a very good choice. When you should use another index is not part of this post.
Concurrent option
Essential is the decision to build the index concurrently or not. But, to decide you need to know the differences of a non-concurrent and a concurrent build. Here we go:
The default CREATE INDEX command builds the index non-concurrently. This means the table will be locked for writeoperations, whereas read operations are still possible. For a production system, this means that your application is unable to persist any data until the index build is finished. CREATE INDEX CONCURRENTLY in contrast, builds the index in a concurrent way, so write operations are still allowed, but at a cost.
How it works in detail
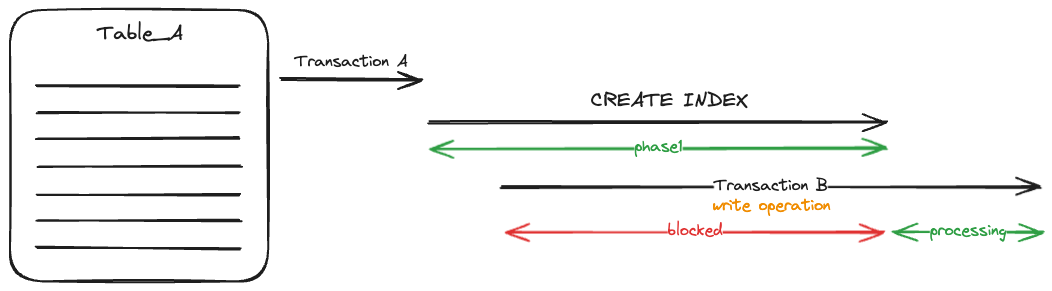
CREATE INDEX locks the table and can build the index with one table scan. It will not be interrupted or have to wait for any other operation, as long as there is no transaction already running that collides with the ExclusiveLock acquired by CREATE INDEX.
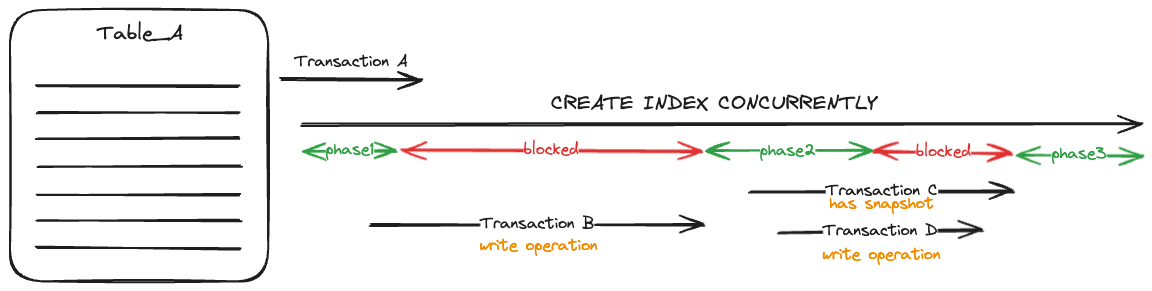
CREATE INDEX CONCURRENTLY works differently; within a first transaction, the index itself is created in the system catalogs and marked as invalid (phase 1). After this, the build process needs two more transactions with one table scan each. Before it can start the second phase (first table scan), it has to wait for any transaction potentially updating data. The third phase (second table scan) might be the most expensive one, as this transaction has to wait for any other transaction to finish, which contains a snapshot. This can even be an index built on an entirely different table. You might think that the index is done after the three phases; that's true, but the index is only usable as soon as any transaction finishes, which predates the start of the index build.
It is important to know, that if a concurrent index creation fails, the invalid index stays and will be updated already. This has an impact on other operations and resource consumption. So take care of removing invalid indexes or ensure to finally create them.
Decision factors
Now you know, at a high level, how both approaches create indexes. Now the big question is, which should I use? As often in engineering, the answer is that it heavily depends on your use case if you build the index concurrently or not. You need to take the following aspects into account to decide:
- Main purpose of the table (read or write heavy)
- Table size
- Complexity of the index itself (single column vs. expression)
- How complex is your database and how easy is it to clean up broken state?
- Does the index creation block your release?
This list of questions/facts is sorted by my opinion of their importance. The first and most important question is: can we accept a possible write lock on the table we want to create the index on? Definitely, this depends on two and three, as this plays into account how long it takes. Unfortunately, I am unable to give a golden number when the size of the table is too big for a non-concurrent index creation. It is the combination of operations running against the table and its size.
Point four and five should not be ignored, as this can have a big impact on when you run such an index creation and what is the impact on your current work.
For us, most tables we created indexes for in the past have been big, which resulted in hours of index creation for some databases. Therefore, we give these questions some more weight to decide which index creation we use. Another fact giving this a higher weight is that we have multiple teams working on this monolithic service. We are managing our database schemas with Liquibase migrations, including index creations. This we do, as we have several instances of our services working on their own database. This is subject to change in the future, but as of today, we have to take this into consideration. Therefore, the index creation is part of our release pipeline, and long-running index builds block following releases until they are done.
We have schema separation for our tenants, which makes the clean-up if concurrent index creation fails more complex. We ran into situations where concurrent index creation failed, and we manually had to clean the state of multiple schemas before we could trigger a new release. Nevertheless, most times, it is less painful than blocking a table against write operations for several hours.
Summary
Concurrent index creation can be really slow. Therefore, it might be worth having a shorter time frame for being blocked with write operations and building the index non-concurrently. If you have a huge table that has a lot of write operations, you might accept the long-running index built while still being able to keep your system running. If you have a table with mostly read operations and occasional updates, you probably should go with the non-concurrent index build.

Published by Nikolas Rist
Visit author page