Mastering Git Merge Strategies: Squash, Merge, and Rebase Explained
Understanding the three git merge strategies and when to use each one can dramatically improve your team's workflow and commit history. Learn the trade-offs between squash, merge, and rebase to make informed decisions for your projects.
In my opinion, git is one of the tools we don't spend enough time mastering. I'm guilty of this too. That's why over the last year, I dedicated time to improving my proficiency with it. During my research, I learned to appreciate the tool more and more, especially when I look back at the old days of using Subversion. Back then, resolving conflicts was a much bigger pain compared to git. Now, after rediscovering git, I sometimes think back to the times when I used it without questioning my workflow.
One such moment was during my time at a Canadian company. We had a process set in stone: squash commits before merging. I never understood why, but I also never questioned it. I just accepted it. Now, in hindsight, I believe I understand the reason. The company had a huge monolith with numerous teams, at least 200 engineers working on the same codebase. The idea was to squash commits to reduce "noise" and create a single commit that could be easily cherry-picked or reverted if needed. While I don't agree with this approach today, I now understand why it was used.
Git Squash
Let's dive deeper into how this process worked. Consider a codebase with two branches for simplicity:
- main (which gets deployed to prod)
- feature/git-merge-techniques (working branch of my feature)
BEFORE (diverged history)
-------------------------
main: A --- B --- C
\
feature: D --- E --- F
AFTER (squash & merge into main)
--------------------------------
main: A --- B --- C --- S
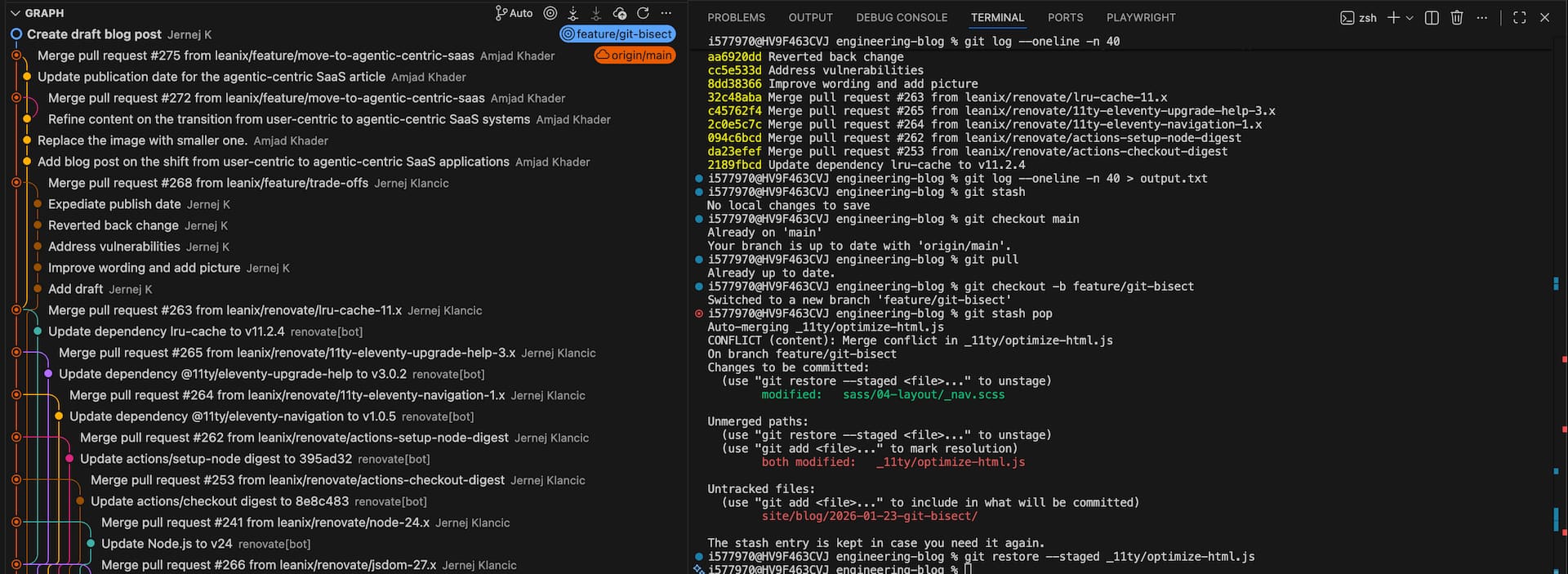
S = (D + E + F combined into one commit)As you can see from the picture, we have two separate branches that diverge. The feature branch has the following git log:
* 5799e3b8 (HEAD -> feature/git-merge-techniques) Improve text flow
* 83e1bcdb Improve wording, grammar and context
* 9cdce2fc Initial draft of our team's journey bringing the MCP server to light
* c56511aa (origin/main, origin/HEAD, main) Merge pull request `#325` from leanix/feature/postgresql-partitioned-tables
|\
| * ab7a6333 Address review comments
| * 10e331ad Add PostgreSQL partitioned tables blog post by George Andrinopoulos
* | 6b565419 Merge pull request `#327` from leanix/renovate/all-minor-and-patch-updates
|\ \
| * | b214b8f0 Update dependency fs-extra to v11.3.5
|/ /
* | cf49af85 Merge pull request `#326` from leanix/renovate/all-minor-and-patch-updates
|\ \
| * | 334964f8 Update All Minor and Patch Updates
|/ /
| | * 8fa05c8b (origin/gh-pages) deploy: c56511aac2a0a679ff17ca8bcb2b986dec2ab9d7
| | * 7493d73f deploy: 6b5654197e709119bb9e6243b2a3f850e0ccb394To merge these changes into main using the squash approach, you would run:
git switch main
git merge --squash feature/git-merge-techniques
git commit -m "Write blog post about merge techniques"This creates a single commit with all changes squashed together. Note that git merge --squash doesn't create a true merge commit; it creates a regular commit without multiple parents. The difference between this and a "normal" merge is that the normal merge preserves all previous commits. This is the "noise" I mentioned earlier.
This approach is still used today, but I'm against it. The best practice is to maintain atomic commits, which give you more control. Imagine needing to revert a change due to a production issue. Reverting a large squashed commit would fix the issue but might also revert other unrelated changes. As engineers, we strive to leave the codebase better than we found it. This means preserving commits as they are, especially when following atomic commit practices. Another downside is that larger commits increase the likelihood of unintended behavioral changes.
However, this doesn't mean I never encourage squashing commits. Squashing is most useful when you have several commits that fix lint issues, test failures, or formatting inconsistencies. In these cases, squashing adds value by consolidating minor cleanup work.
Since we've mentioned three techniques, let's discuss the other two: git merge and git rebase. Both preserve the commits within a feature branch, but they handle history differently.
Git Merge
With git merge, you create a new "merge commit" that combines two branches (in our case, main and feature/git-merge-techniques).
BEFORE (diverged history)
-------------------------
main: A --- B --- C
\
feature: D --- E
AFTER (git merge feature into main)
-----------------------------------
main: A --- B --- C -------- M
\ /
feature: D --- E --
M = (new commit combining both histories)This merge commit has exactly two parent commits: one pointing to the tip of the main branch and one pointing to the tip of the feature branch. This preserves the entire history of both branches, showing when they diverged and when they came back together. The advantage is that you preserve not only the commit hashes but also the branching structure and commit order. In most companies I've worked with, this was the default mechanism for merging features. You can see this in the log above:
* c56511aa (origin/main, origin/HEAD, main) Merge pull request `#325` from leanix/feature/postgresql-partitioned-tables
|\
| * ab7a6333 Address review comments
| * 10e331ad Add PostgreSQL partitioned tables blog post by George Andrinopoulos
* | 6b565419 Merge pull request `#327` from leanix/renovate/all-minor-and-patch-updates
|\ \
| * | b214b8f0 Update dependency fs-extra to v11.3.5
|/ /
* | cf49af85 Merge pull request `#326` from leanix/renovate/all-minor-and-patch-updates
|\ \
| * | 334964f8 Update All Minor and Patch Updates
|/ /
| | * 8fa05c8b (origin/gh-pages) deploy: c56511aac2a0a679ff17ca8bcb2b986dec2ab9d7
| | * 7493d73f deploy: 6b5654197e709119bb9e6243b2a3f850e0ccb394The key benefit of git merge is that you only resolve conflicts once, within the merge commit itself, to determine which code takes precedence.
Git Rebase
git rebase, on the other hand, changes the base of your feature branch by replaying your commits on top of the latest main branch. Unlike git merge, which creates a merge commit, git rebase creates a perfectly linear history by rewriting the feature branch's commit history.
BEFORE (diverged history)
-------------------------
main: A --- B --- C
\
feature: D --- E
AFTER (git rebase main)
------------------------
main: A --- B --- C --- D' --- E'
D', E' = (rebased copies of D, E)It takes the commits from your feature branch and applies them one by one on top of the target branch, creating new commit hashes in the process. After running git rebase main on the feature branch, the log would look like this:
* f3a8c21e (HEAD -> feature/git-merge-techniques) Improve text flow
* 9d4b7f05 Improve wording, grammar and context
* 2e6a1c83 Initial draft of our team's journey bringing the MCP server to light
* c56511aa (origin/main, origin/HEAD, main) Merge pull request `#325` from leanix/feature/postgresql-partitioned-tablesThe downside is that if you want to keep your feature branch up to date with main, you need to rebase whenever there are new changes you want to incorporate. In a large codebase with many contributors, you'll likely need to rebase frequently to stay current. Even worse, you might need to resolve the same conflict multiple times during a rebase, since each commit from the feature branch is replayed individually. Git applies your commits one at a time, so if multiple commits touch the same code that conflicts with main, you'll need to resolve conflicts for each commit separately.
Conclusion
Each merge strategy has its place:
- Squash merging works well for consolidating cleanup commits but can make reverting specific changes difficult
- Regular merging preserves full history and branching structure, making it ideal for collaborative workflows
- Rebasing creates clean, linear history but requires more conflict resolution effort
Choose the strategy that best fits your team's workflow and the specific situation at hand.
Published by...

Jernej Klancic
Visit author page